
Category: IGCSE Biology posts

Air Pollution part 1: Grade 9 understanding for IGCSE Biology 4.12
The extended topic on “Human Influences on the environment” is one that is well worth revising thoroughly. I haven’t done any analysis of past papers (life is too short) but my hunch is that questions on these topics have been over-represented in the past few years. This first blog post on air pollution is just going to summarise the consequences of pollution of the atmosphere by one gas – sulphur dioxide. I apologise but I cannot bring myself to spell it sulfur dioxide as it is in the specification – old man syndrome I’m afraid…..
Sulphur Dioxide
99% of the sulphur dioxide in the air comes from human sources. It is an acidic gas that acts as a pollutant in two ways. Firstly direct on human lungs and airways where it is an irritant and can cause wheezing, tightness in the chest and lead to lung disease. This can be a particular problem for people already suffering with asthma and other diseases of the lung. Sulphur dioxide (along with various oxides of nitrogen) is also a major contributor to the environmental problem of acid rain.
Sulphur dioxide is produced when any fossil fuel containing sulphur is burned. The biggest contributor of this pollutant gas (~70% of the total emissions) is the industrial combustion of coal and natural gas for electricity production. ~20% of total emission comes from other industrial processes and the remainder from burning petrol and other domestic fossil fuels.

The major environmental problem with sulphur dioxide is acid rain.

Sulphur dioxide and various nitrogen oxides are released from coal-fired power stations when coal is burned. These gases can react in the atmosphere under the influence of radiation from the sun and then dissolve in water to form sulphuric and nitric acids. These then cause the rainfall to be excessively acidic and this often occurs long distances from where the pollutants were released.
NB All rainfall is slightly acidic due to carbon dioxide in the atmosphere forming carbonic acid. Acid rain is therefore defined as rainfall (or other precipitation such as snow or hail) with a pH of less than pH5.6.

What are the consequences of acid rain?
As shown in the picture above, there are several biological impacts of acid rain.
Acid rain can cause coniferous trees (e.g. pine trees) to lose their needles (leaves). This will kill the tree as it cannot photosynthesise and so has led to deforestation in certain parts of the world.
Acid rain leaches minerals (e.g calcium and potassium )from the soil more effectively than normal rain. This leaves the soil very low in certain essential minerals and so makes it harder for plants to grow.
The minerals leached can then themselves become pollutants in fresh water. Aluminium ions in fresh water can cause fish to overproduce mucus in their gills. This will kill adult fish as they cannot get enough oxygen into their blood. Fish eggs will not survive in acidic water and many small invertebrates are also killed directly by the acidity. So freshwater ecosystems can collapse.
Starch Digestion: Grade 9 Understanding for IGCSE Biology 2.29
You must remember that “Digestion” has a specific meaning in Biology. It is the term used for the process that involves the chemical breakdown of large, insoluble food molecules into smaller, simpler molecules that can be absorbed into the blood. Many of the molecules in food are polymers – that is macromolecules made from long chains of repeating subunits. Examples of dietary macromolecules include proteins, polysaccharides and fats. These molecules are too large to be able to pass into the blood in the villi of the small intestine and so the body has evolved to chemically break them down into their constituent monomers or building blocks. Digestion is the process in the alimentary canal that achieves this.
Digestion reactions are also known as hydrolysis reactions because a molecule of water is required in the reaction to break the covalent bond holding the monomers together. These reactions are all catalysed (sped up) by specific molecules called digestive enzymes.
Why do different food types need different digestive enzymes to speed up their breakdown in the digestive system?
(If you are unsure, you need to revise the way enzymes work to catalyse reactions by a “lock and key” theory?)
Digestion of Carbohydrates
Many simple carbohydrates (e.g. glucose) do not need digesting. This is because they are already small enough to be absorbed into the blood directly in the ileum (small intestine). But larger disaccharide sugars (e.g. maltose and sucrose) do need to be broken down, as do all polysaccharides (e.g starch).
The family of enzymes that break down carbohydrates are called carbohydrases.
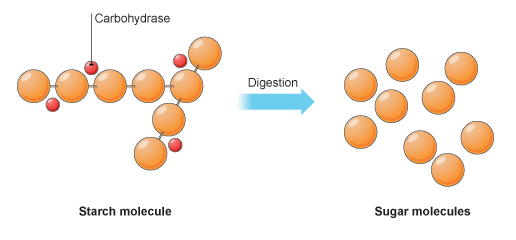
Starch is a large polysaccharide made up of many hundreds of glucose residues linked together. It is way too big to be able to cross the epithelial lining of the small intestine and so needs to be digested. This happens in a two-stage process. Firstly there is an enzyme amylase that can catalyse the following reaction:
starch + water ——-> maltose
Amylase is made in the salivary glands and so works in the mouth. But the main region for the digestion of starch is in the duodenum. This is because amylase is also made in the pancreas.
Maltose is a disaccharide molecule made of two glucose residues joined together. Maltose itself requires digesting to its constituent glucose molecules in order to be absorbed. So the second stage in the digestion of starch involves a second enzyme, maltase that is found embedded into the epithelial lining of the ileum. Maltase catalyses the breakdown of a molecule of maltose into two molecules of glucose which can be absorbed into the blood.
maltose + water ——> glucose


Cell Structure: Grade 9 Understanding for IGCSE Biology 2.2 2.3 2.4
All living organisms are made from cells. Indeed the cellular nature of life is one of the universal features shared by all life on earth. Some organisms are made from just one cell (unicellular organisms) while at some point around 1 billion years ago, cells starting clumping together and specialising to form multicellular organisms such as animals and plants.
What do all cells have in common?
All cells are surrounded by a cell membrane. The cell membrane is made from a mixture of proteins and a type of lipid called a phospholipid. The cell membrane serves many functions but perhaps the most significant is acting as a partially permeable barrier that can control which molecules can enter and leave the cell.
Inside the cell membrane there is a watery solution of chemicals called the cytoplasm. The cytoplasm is the site of many metabolic reactions in the cell because many enzymes are dissolved in the cytoplasm. The cytoplasm also contains many tiny nano machines for assembling proteins called ribosomes.
And that is about it for things all cells have in common. Prokaryote cells (bacteria) have a very different cell structure with no organelles but in this section you need to understand the simplified structure of two eukaryote cells: a typical animal (on the left below) and a typical plant cell (on the right).

Both animal and plant cells have a nucleus. This is the largest organelle and contains the DNA which is the genetic material. The DNA is found in long thread-like structures called chromosomes. The nucleus controls the division of the cell and also the various functions of the cell by regulating which proteins get made.

Animal and Plant cells both contain mitochondria which are the organelles associated with aerobic respiration. Mitochondria are recognisable in the cytoplasm of the cell as sausage-shaped organelles with a folded inner membrane (see diagram above).

Structures found only in Plant cells
1) All plant cells have a thick rigid cell wall made of the carbohydrate cellulose. The cell wall allows plant cells to become turgid since when the cell takes in water by osmosis, the rigid cell wall prevents the cell from bursting. The cell wall also acts as a transport pathway across plant tissues and can provide a barrier to some pathogens.
2) All plant cells have a large permanent central sap vacuole. This organelle is bounded by a membrane called the tonoplast and in many plant cells takes up the majority of the volume of the cell.

The sap vacuole provides a compartment in the cell into which excretory molecules can be moved to stop them poisoning the cytoplasm. It also plays a role in the water balance of plant cells since because of all the solute dissolved in it, the cell sap has a low water potential. This helps draw in water by osmosis from the cytoplasm and hence from outside the cell across the cell membrane.
3) Many but not all plant cells contain chloroplasts. These are organelles associated with the process of photosynthesis. Chloroplasts can be recognised in a light microscope image as small, green structures in the cell. The green pigment comes from the chlorophyll molecules that trap energy from sunlight. In an electron micrograph, chloroplasts are distinguished due to their stacks of membrane discs called grana.



Differences between plant and animal cells

The Human Alimentary canal: Grade 9 Understanding for IGCSE Biology 2.27
A human body is in many ways rather like a packet of polo mints. These are famous mints in the UK for having a hole in the middle. Our body is divided into segments (rather like the packet of polos) and we have a tube that runs through the middle of us. This tube is called the Alimentary Canal (or Gut) and it’s function in the body is the digestion and absorption of food molecules (see later post on “Stages of Processing Food”)

The Alimentary Canal is divided into specialised regions, each with its own particular range of functions to do with the processing of food. You are required to understand a little about some of these organs and their functions.

The first thing is to make sure you can label a diagram of the human digestive system such as the one shown above. Check that you could accurately identify the following structures:
mouth, tongue, teeth, salivary glands, oesophagus, stomach, liver, gall bladder, bile duct, pancreas, pancreatic duct, duodenum, ileum, colon, appendix, rectum, anus
Here is a good diagram to use to check your labelling of the human digestive system

Functions
1 Mouth
The mouth is actually the name for the opening at the top of the alimentary canal rather than the chamber behind. If you want to be really precise, you should call this chamber containing the tongue and teeth by its proper name, the buccal cavity. The mouth is the opening that allows an animal to ingest food. In the buccal cavity, the teeth can chop up the food into smaller pieces and the tongue can move the food into a ball (bolus) for swallowing. The food is tasted in the buccal cavity and there are many chemoreceptors on the tongue and in the nasal cavity that perform this function. There are three sets of salivary glands around the buccal cavity and these secrete a watery liquid, saliva to mix with the ingested food. Saliva is alkaline to help protect the tooth enamel from acidic decay by bacteria but also contains a digestive enzyme, salivary amylase that begins the process of digestion of starch in the mouth. Salivary amylase catalyses the hydrolysis reaction in which starch, a polysaccharide is digested into the disaccharide maltose.
2 Oesophagus
The oesophagus is the tube that carries the ball of food from the back of the throat through the thorax and down into the stomach. The Alimentary canal has layers of muscle in its wall throughout its entire length. These layers of smooth muscle can contract and relax in an antagonistic fashion to push the bolus along the tube. There are two main types of smooth muscle in the wall of the Alimentary canal – circular fibres are arranged around the circumference of the tube and longitudinal fibres are arranged along the length of the tube. These waves of alternate contraction and relaxation are called peristalsis.
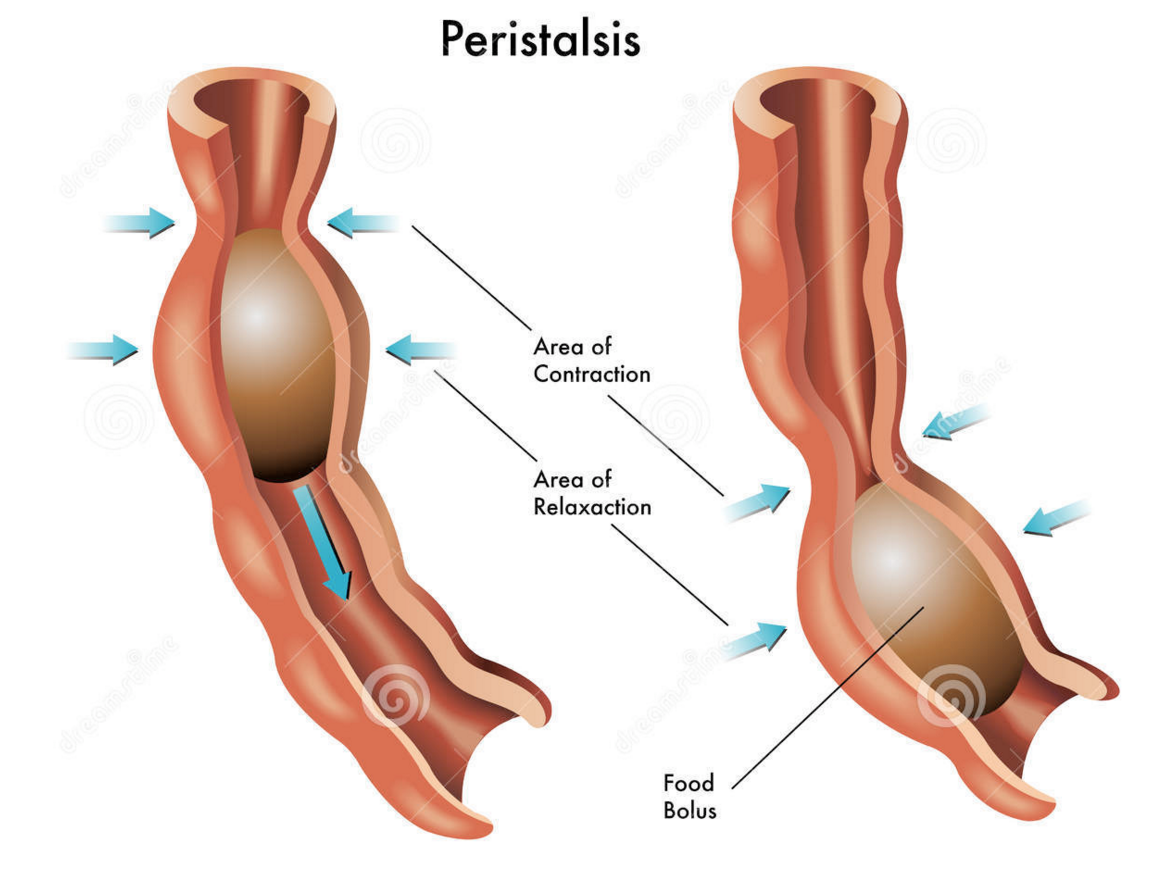
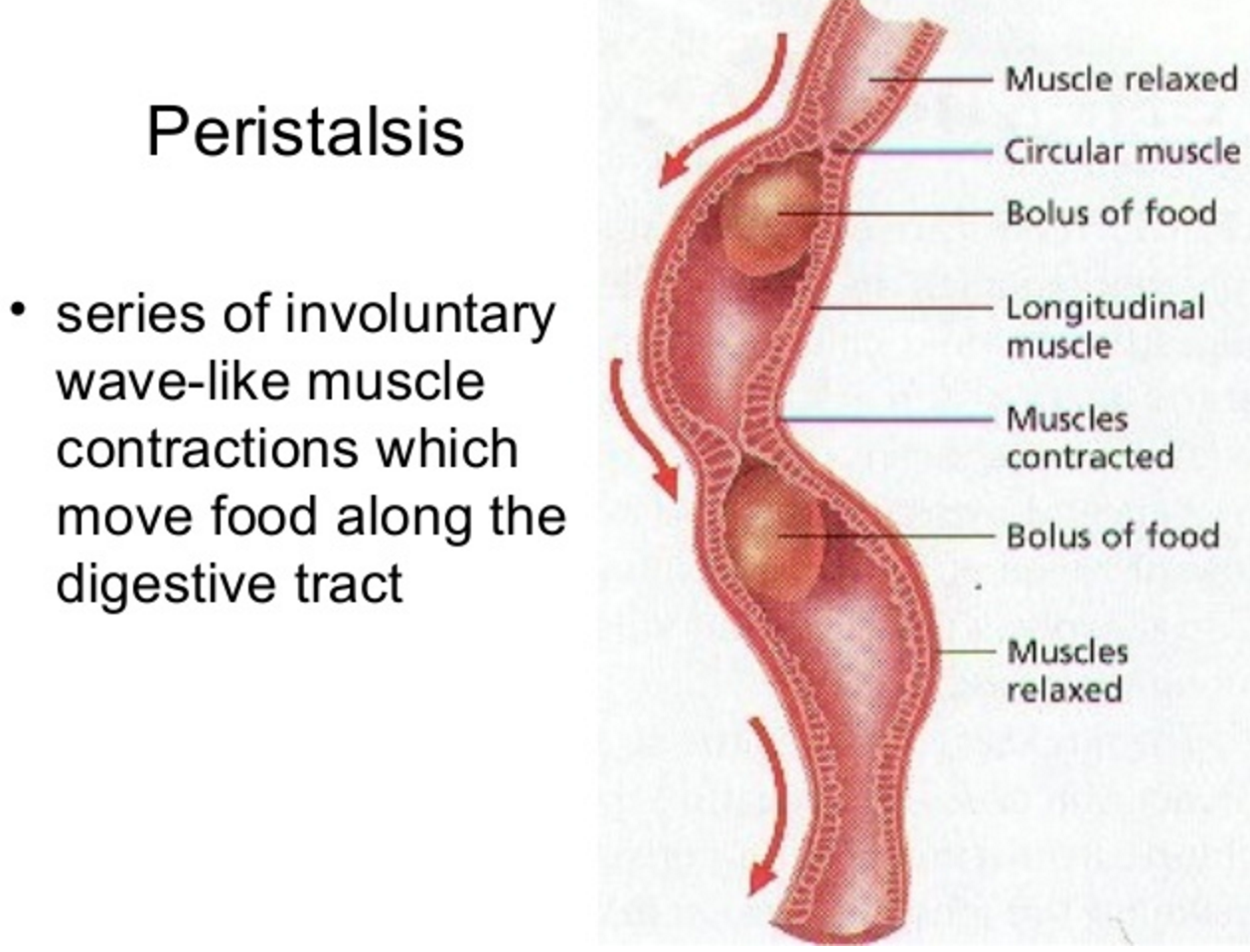
3 Stomach
The stomach is a muscular storage organ that keeps food in it for around 3-4 hours before squirting it out in small amounts into the duodenum. The muscle layers in the stomach wall churn the food and mix it with the secretions from the stomach lining. These secretions are called gastric juice and contain a mixture of hydrochloric acid, mucus and a digestive enzyme pepsin. The acid makes the gastric juice overall very acidic, around pH 1.5. This acidity forms part of the non-specific defences of the body against bacteria as the extreme pH kills almost all bacteria in the food. The mucus is important as it protects the cells lining the stomach from the acidity. Pepsin is a digestive enzyme that starts the digestion of protein. It catalyses a hydrolysis reaction in which proteins are broken down into smaller molecules called polypeptides. Pepsin is an unusual enzyme in that it has an optimum pH of around 1.5.
4 Small Intestine
I will write a whole post on the small intestine later this week as there is plenty for you to understand about this part of the alimentary canal. All I will say here is that it is divided into the duodenum which is where almost all the digestion reactions take place and the ileum which is adapted for efficient absorption of the products of digestion into the blood. (see post later in the week if you want to find out more….)
5 Large Intestine
The majority of the large intestine is made up of an organ called the colon. The colon has a variety of functions. It is where water from all the various secretions is reabsorbed back into the blood, thus producing a solid waste called faeces. (Water that you drink tends to be absorbed through the stomach lining much earlier in the alimentary canal) There are also a few mineral salts and vitamins absorbed into the bloodstream in the colon. The colon is also home to a varied population of bacteria, the so called gut flora. Faeces is stored in the final part of the large intestine that is called the rectum.
6 Pancreas
The pancreas is not part of the alimentary canal (although I am not sure the person who wrote the specification appreciated that….) It is an example of what is called an accessory organ for the digestive system. The pancreas is a really interesting organ as it contains different cell types that carry out two completely separate functions. The majority of the cells in the pancreas secrete a whole load of digestive enzymes into an alkaline secretion called pancreatic juice. There is a tube called the pancreatic duct that carries the pancreatic juice and empties it into the duodenum where it can mix with the acidic chyme coming out of the stomach.
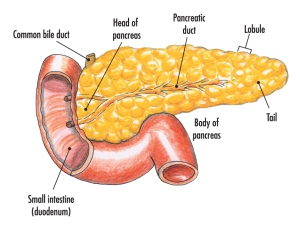
There are small clusters of a different kind of cell found in the pancreas. These are the islets of Langerhans that secrete the hormones insulin and glucagon into the bloodstream. These two pancreatic hormones together regulate the blood glucose concentration.
Hormones: Grade 9 Understanding for IGCSE Biology 2.94 2.95B
Hormones are defined as “chemicals produced in endocrine glands that are secreted into the bloodstream and cause an effect on target tissues elsewhere in the body”. They play a wide variety of roles in the healthy functioning and development of the body.

The iGCSE specification only really mentions a small number of hormones so these are the ones I will focus on in this post.
ADH (anti-diuretic hormone) (Separate Biologists only – not Combined Science)
ADH is secreted into the blood by an endocrine gland at the base of the brain called the Pituitary Gland. The stimulus for the release of ADH into the blood comes from the hypothalamus (a region of brain right next to the pituitary gland) when it detects that the blood plasma is becoming too concentrated. This might be caused by the body becoming dehydrated due to sweating. ADH travels round the body in the blood until it reaches its target tissue which are the cells that line the collecting ducts in the nephrons in the kidney. ADH increases the permeability of the connecting duct walls to water, thus meaning more water is reabsorbed by osmosis from the urine in the collecting duct and back into the blood. This results in a small volume of concentrated urine being produced.
Adrenaline
Adrenaline is secreted into the blood by the adrenal glands in situations of danger or stress.. The adrenals are found just above the two kidneys on the back of the body wall. Adrenaline secretion is controlled by nerve cells that come from the central nervous system. Adrenaline is often described as the “fight or flight” hormone as its effects are to prepare the body to defend itself or run away from danger. There are receptors for adrenaline in many target tissues in the body but some of the most significant effects of adrenaline are:
- affects the pacemaker cells in the heart causing an increase in heart rate
- shifts the pattern of blood flow into muscles, skin and away from the intestines and other internal organs
- decreases peristalsis in the gut
- causes pupils to dilate in the eye
- increases breathing rate in the lungs
- promotes the passing of urine from the bladder
Insulin
Insulin is a hormone made in the islets of Langerhans in the pancreas. It plays a vital role in the homeostatic control of the blood sugar concentration. The pancreas will secrete insulin into the blood when the blood glucose concentration gets too high. There are many cells in the body with insulin receptors but the main target tissue for insulin is the liver.
Insulin causes the liver (and muscle) cells to take glucose out of the blood and convert it into the storage polysaccharide glycogen. This results in a lowering of the blood glucose concentration: a good example of the importance of the principle of negative feedback in homeostasis
Testosterone
Testosterone is a steroid hormone made by cells in the testes of males. It is the main hormone of puberty in males resulting in the growth of the reproductive organs at puberty as well as the secondary sexual characteristics (pitch of voice lowering, muscle growth stimulated, body hair grows etc.)
Oestrogen
Oestrogen is a steroid hormone made by the cells in the ovary that surround the developing egg cell in the first half of the menstrual cycle. In puberty it causes the development of the female secondary sexual characteristics (breast growth, change in body shape, pubic hair etc.) but in the menstrual cycle, oestrogen has a variety of important effects. It stimulates the rebuilding of the uterine endometrium (or lining) to prepare the uterus for the implantation of an embryo. Oestrogen also affects the pituitary gland and can cause the spike in LH concentrations that trigger ovulation on day 14 of the cycle.
Progesterone
Progesterone is also made in the ovary but at a different time in the menstrual cycle. It is secreted by cells in the corpus luteum, a structure found from day 14 onwards after the egg has been released in ovulation. Progesterone has two main target tissues: it maintains the thickened lining of the endometrium in the uterus ready for implantation. Progesterone also causes the pituitary gland to stop secreting the hormones FSH and LH so a new cycle is never started. It is for this reason that progesterone can be used in women as a contraceptive pill.
FSH (Follicle-Stimulating Hormone (Separate Biologists only – not Combined Science)
FSH is a hormone released by the pituitary gland underneath the brain. The target tissues for FSH are in the testis (males) and ovaries (females). In males FSH plays a role in the growth of the testes allowing sperm production to start. In females, FSH is the hormone released at the start of the menstrual cycle that causes one of the immature egg cells in an ovary to grow, develop and so become surrounded by follicle cells prior to ovulation.
LH (Luteinising Hormone) (Separate Biologists only – not Combined Science)
LH is a second reproductive hormone released by the pituitary gland into the bloodstream. In males, it stimulates the production of testosterone in the testes. In females, it is released only on days 13 and 14 of the menstrual cycle and it is the hormone that triggers ovulation.
Comparing Nervous and Hormonal Coordination: Grade 9 Understanding for IGCSE Biology 2.86
This topic requires you to understand how nervous and hormonal coordination compare and to understand the differences between the two systems.
Coordination is the life process by which organisms can detect and respond to a change in the environment. These changes in the environment that can be detected are called stimuli. A stimulus can be outside the body (e.g. the air temperature dropping) or internal (e.g. an increase in the concentration of glucose in the blood after a meal).
How do organisms detect and respond to stimuli?
There are two systems that can bring about coordination:
- Nervous System
- Hormonal System (also known as the Endocrine system)
The nervous system is made up of around 100 billion specialised cells called neurones. Neurones (nerve cells) are adapted in that they can transmit an electrical event called nerve impulse (or sometimes an action potential) rapidly from one end of the cell to the other. You should understand the simplest pattern of nervous coordination which is called a reflex arc.

The hormonal system works in a completely different way. There are no electrical impulses in the hormonal system. A hormone is a chemical that is released into the blood stream and exerts an effect at a target tissue elsewhere in the body.
Have a read of my blog post on hormones to find out more…..

If you understand how these two systems are able to link one part of the body to another, then you can see how these two compare.

The first rows in the table have already been discussed.
Because the nerve impulse travels along a neurone at up to 100 m/s you can see that the nervous response will be much faster than a hormone that is secreted into the blood. It can take up to a minute or two for a hormone to travel from the secreting cell to the target cell. So nervous coordination is fast, hormonal is slow.
The response to a nervous signal often only lasts for a short time. Nervous responses tend to be muscle contractions and these are temporary of course. Hormones on the other hand often are involved in longer term processes like growth and development. As an example, think of the changes brought about at puberty by the hormones testosterone (in men) and oestrogen (in women).
Finally you can compare where the response occurs. Nerve cells can only cause a response at the exact point where they end. They release neurotransmitters into a synapse and this exerts an effect on the next neurone or muscle cell. Because hormones are released into the blood plasma, and blood is carried everywhere in the body, a single hormone can effect many targets in the body. For example, adrenalin (epinephrine for our American cousins) is a hormone released by the adrenal gland above the kidneys. But the target tissues for adrenalin are found all over the body – e.g. the heart, the skeletal muscles, the iris in the eye, the hairs in the skin, the lungs, the liver etc. Read more about adrenalin in my blog post here.
I hope this helps….. Please leave a comment in the box below to either give me some feedback, give me some suggestions for future posts or to ask a question.
Chromosomes and Sex: Grade 9 Understanding for IGCSE Biology3.26 3.27
Having spent the last day or two writing material about one of the hardest topics in the IGCSE Biology specification (DNA and Protein Synthesis), I am going to write today about something much simpler. You need to understand how the sex of a human is determined at the moment of fertilisation. But this is a topic which can confuse students so I am going to try to explain it for you as best I can.
The sex of a human (whether male or female) is determined by the 23rd pair of chromosomes. Please remember that just because humans determine their sex this way, this doesn’t mean that other species have to be the same. In fact other species use a variety of ways to ensure the correct proportion of male and offspring are born.
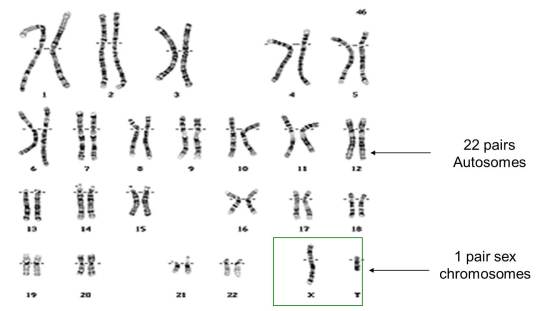
As you can see from the picture above, the 23rd pair of chromosomes in humans are called the sex chromosomes. The person whose chromosomes are shown above is male because he has one X and one Y chromosome in his 23rd pair. If we looked at a picture of a human female set of chromosomes, pairs 1 to 22 would be exactly as above, but the 23rd pair would be different. There would be two large X chromosomes rather than one large X and one tiny Y chromosome as shown above.
So a human female has XX as her 23rd pair of chromosomes, a human male has XY as his 23rd pair.
Gametes (Sperm and Egg cells) are made in a process called Meiosis. Remember that meiosis produces daughter cells that are haploid (this means they only have one member of each pair of chromosomes and so half the genetic material)
When a female cell undergoes meiosis in her ovary, the daughter cells produced (egg cells) will contain one of each of the 23 pairs of chromosomes. For the 23rd pair this will always be an X chromosome since both chromosomes in the 23rd pair are X chromosomes.
When a male cell undergoes meiosis in the testis, the daughter cells produced (sperm cells) will contain one of each of the 22 pairs of chromosomes exactly as above. But the 23 pair are different to each other and so half the sperm cells will contain an X chromosome as the 23rd chromosome and half the sperm cells will contain a Y chromosome as the 23rd chromosome.

If you understand the picture above, you understand sex determination in humans. You also need to be able to draw a genetic diagram to show this.
Phenotype: Mum Dad
23rd pair: XX XY
Gametes: X ½X ½Y
Fertilisation:

Offspring 23rd pair of chromosomes: ½ XX and ½ XY
Offspring phenotypes: ½ female and ½ male
Protein Synthesis (part 3): Grade 9 Understanding for IGCSE Biology 3.18B
This is my final post on protein synthesis, you may be relieved to know…. It is a complicated topic and there is lots to understand but remember it is only one specification point out of several hundred in the IGCSE specification…… So don’t worry too much if you find this hard to grasp and don’t spend a disproportionate amount of time revising it. If you are fascinated by how genetic information is encoded in DNA and how genes work at a molecular level, then you have to choose Biology as a subject to study at A level!
I want to end with two final questions, both of which are essential to address if you are to acquire the grade 9 understanding you need.
What is meant by complementary base pairing and why is it so important?
Let’s go back to the structure of a DNA molecule.
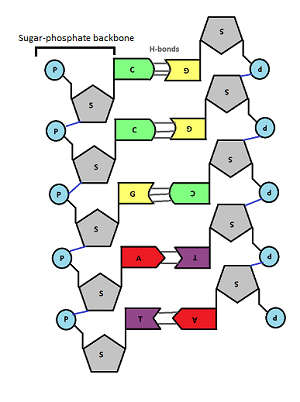
In the middle of the molecule there are pairs of bases. There are four possible bases in DNA – Adenine, Thymine, Cytosine and Guanine – but they are often represented by their letters A,T,C and G.
Bases pair up in a totally predictable way across the double stranded DNA molecule:
A always pairs with T, C always pairs with G. Why is this? Well you can see from the diagram above that A and T are held together by two weak bonds called Hydrogen (H) bonds, whereas C and G are held together by 3 H bonds. This means that this is the only way they can pair up in a stable way.
These pairs of bases (A=T and C≡G) are called complementary base pairs because they always match up in a predictable way.
You can also get complementary base pairing between RNA bases. (Remember that in RNA, there is never any thymine but it is replaced with a different base called uracil) So A=U and C≡G are the complementary base pairs between two RNA molecules.
Complementary base pairing between DNA and RNA bases is essential in transcription but you do not need to know the details at this stage.
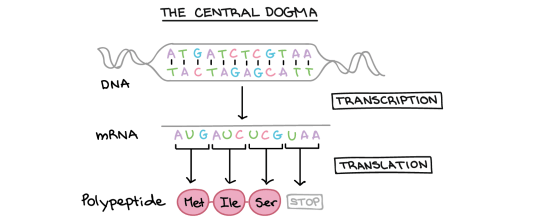
We will come back to complementary base pairing in a moment…..
How does the ribosome ensure that the correct amino acids are joined together to make the protein during translation?
To understand this, you need to understand the role that transfer RNA (or tRNA for short) plays in protein synthesis. tRNA molecules are found in the cytoplasm and have an interesting structure. At one end, they have an important triplet of bases called the anticodon. At the other end, there is a place in the molecule where an amino acid can be added.

The key idea is this: the tRNA molecules are loaded up by attaching an amino acid by a group of enzymes found in the cytoplasm. But these enzymes ensure that each amino acid is only attached to tRNA molecules with the correct anticodon.
Transfer RNA molecules are so called because they are going to transfer (or carry) the amino acids into the ribosome. You do not need to know the details of protein synthesis but the main idea is that there is complementary base pairing between the anticodon on the tRNA and the codon on the mRNA.
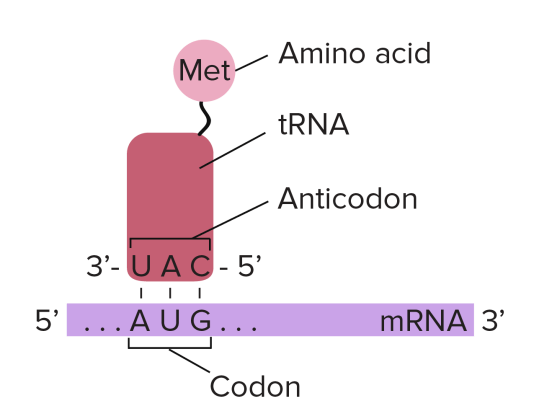
This complementary base pairing between codon and anticodon when combined with the structure of the ribosome means that the amino acids will be joined together in the correct order to make the protein.
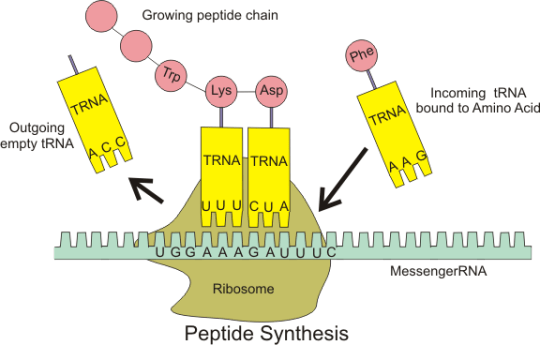
Please do not worry too much about the details of all this. I am sure that the examiners will not expect you to know the details of protein synthesis. But you should understand what an an anticodon is and the role of tRNA in the overall process.
anticodon: “a triplet of adjacent bases found on a transfer RNA molecule”
tRNA: “these molecules are found in the cytoplasm of cells and carry the correct amino acid into the ribosome. There is complementary base pairing between the codon on the mRNA and the anticodon on the tRNA as shown in the diagram above”
Protein Synthesis (part 2): Grade 9 Understanding for IGCSE Biology 3.18B
In the last post, I asked you to think of a good “2 mark” explanation of some important terms to do with protein synthesis. Here is my (GCSE level) answer…..
Gene: “a section of a DNA molecule that codes for the production of a single protein”
Ribosome: “a small structure found in the cytoplasm of cells where proteins are made by joining amino acids together into a long chain”
Transcription: “the process occurring in the nucleus in which a double-stranded DNA molecule is used to make a single-stranded molecule of messenger RNA”
Messenger RNA: ” a small single stranded molecule that is made in transcription and can carry the genetic information out of the nucleus to the ribosome”
Translation: “the second stage of protein synthesis that occurs in the cytoplasm in a ribosome in which amino acids are joined together in the correct order to make the protein”
Codon: “a triplet of adjacent bases in an mRNA molecule that codes for a single amino acid”
Finally I want to answer three important questions, one in this post, two in the next….
Why are codons three bases long?
Well, the answer here is a simple bit of Maths. If you remember, there are 20 possible amino acids that can be joined together in any order and in any number to make a protein. In DNA/RNA there are just four bases. So in order to code for 20 amino acids, how many “words” do you need? Well you need at least 20…..
In DNA/RNA you only have 4 “letters” available to make these words. (The letters are the bases and the words are the codons.)
- If the words were one letter long, there are only 4 words. (43 for the mathematicians): A,T,C,G
- If the words were two letters long, there are only 16 possible words (42 for the mathematicians): AA, AT, AC, AG, CA, CT, CC, CG, GA, GT, GC, GG, TA, TT, TC, TG
- If the words were three letters long, there are 64 possible words (43 for the mathematicians) AAA, AAT, AAC, AAG, ACA, ACT, ACC, ACG etc. etc.
So three bases in a codon is a minimum number needed to code for 20 different amino acids. But then this raises a question, doesn’t it? If there are 64 possible words and only 20 words needed, then what happens to all the extra, unnecessary codons? The answer is that there are lots of synonyms in the language of DNA/RNA. (Synonyms are two different words that have the same meaning)
Check out this picture of the genetic code (written in the language of RNA) and notice all the lovely synonyms!

Phe, Leu, Ser, Tyr, Cys and the others are names of amino acids
Notice that almost all amino acids have more than one codon that codes for them. For example, the amino acid Thr (threonine) is coded for by ACU, ACC, ACA and ACG in mRNA.
The three codons marked STOP are used as signals for the ribosome to stop the process of translation (but you don’t need to worry about that unless you wisely choose to continue your studies in Biology at A level!)
This is complicated stuff so please feel free to ask me questions about this using the “leave a comment” box below. You won’t get an instantaneous response but I try to check my blog every couple of days.
RNA: Grade 9 Understanding for IGCSE Biology 3.17B
You need to understand the structure of the molecule DNA before you read this post.
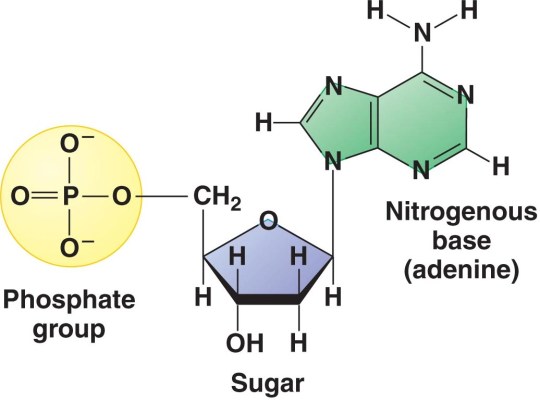
DNA stands for deoxyribonucleic acid and is the chemical that makes up the genetic information in all living organisms on earth. DNA is a double-stranded molecule in which each strand is made of a polymer of simple molecules called nucleotides. There are four nucleotides in DNA, with each nucleotide differing in the base present in the molecule. Adenine, Thymine, Cytosine and Thymine are the four bases found in the nucleotides in DNA. Every nucleotide in DNA contains the same sugar, deoxyribose and a phosphate group as shown in the diagram below.
But DNA is not the only nucleic acid found in cells. All living cells also contain a similar molecule RNA that serves a whole variety of different functions. It is not the main genetic material in any cell but is essential in allowing the information contained in a DNA molecule to be expressed as a protein (see post on protein synthesis to come)
RNA stands for Ribonucleic Acid and is also a polymer of nucleotides. But whereas DNA is always a double-stranded molecule, RNA is always single-stranded (although certain forms of RNA can fold back on themselves at points so they can appear double stranded). The sugar in every RNA nucleotide is ribose (as opposed to deoxyribose in DNA).

There are also four different bases found in RNA nucleotides. Three are identical to the bases found in DNA (Adenine, Cytosine and Guanine) but there is no Thymine in RNA. RNA can contain nucleotides with the similar base Uracil in its place.

So in summary:
- RNA is single stranded whereas DNA is double stranded
- RNA contains the sugar ribose in every nucleotide whereas DNA contains deoxyribose
- DNA contains 4 bases (ATCG) whereas RNA contains A,U,C and G (thymine is replaced by uracil)
