
Tagged: DNA
Protein Synthesis (part 3): Grade 9 Understanding for IGCSE Biology 3.18B
This is my final post on protein synthesis, you may be relieved to know…. It is a complicated topic and there is lots to understand but remember it is only one specification point out of several hundred in the IGCSE specification…… So don’t worry too much if you find this hard to grasp and don’t spend a disproportionate amount of time revising it. If you are fascinated by how genetic information is encoded in DNA and how genes work at a molecular level, then you have to choose Biology as a subject to study at A level!
I want to end with two final questions, both of which are essential to address if you are to acquire the grade 9 understanding you need.
What is meant by complementary base pairing and why is it so important?
Let’s go back to the structure of a DNA molecule.
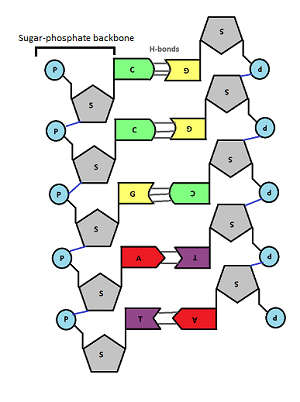
In the middle of the molecule there are pairs of bases. There are four possible bases in DNA – Adenine, Thymine, Cytosine and Guanine – but they are often represented by their letters A,T,C and G.
Bases pair up in a totally predictable way across the double stranded DNA molecule:
A always pairs with T, C always pairs with G. Why is this? Well you can see from the diagram above that A and T are held together by two weak bonds called Hydrogen (H) bonds, whereas C and G are held together by 3 H bonds. This means that this is the only way they can pair up in a stable way.
These pairs of bases (A=T and C≡G) are called complementary base pairs because they always match up in a predictable way.
You can also get complementary base pairing between RNA bases. (Remember that in RNA, there is never any thymine but it is replaced with a different base called uracil) So A=U and C≡G are the complementary base pairs between two RNA molecules.
Complementary base pairing between DNA and RNA bases is essential in transcription but you do not need to know the details at this stage.
We will come back to complementary base pairing in a moment…..
How does the ribosome ensure that the correct amino acids are joined together to make the protein during translation?
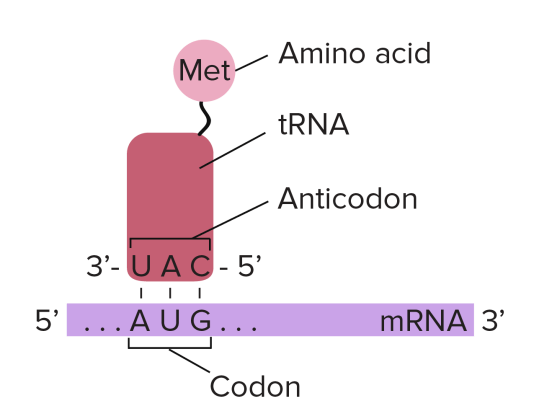
To understand this, you need to understand the role that transfer RNA (or tRNA for short) plays in protein synthesis. tRNA molecules are found in the cytoplasm and have an interesting structure. At one end, they have an important triplet of bases called the anticodon. At the other end, there is a place in the molecule where an amino acid can be added.

The key idea is this: the tRNA molecules are loaded up by attaching an amino acid by a group of enzymes found in the cytoplasm. But these enzymes ensure that each amino acid is only attached to tRNA molecules with the correct anticodon.
Transfer RNA molecules are so called because they are going to transfer (or carry) the amino acids into the ribosome. You do not need to know the details of protein synthesis but the main idea is that there is complementary base pairing between the anticodon on the tRNA and the codon on the mRNA.
This complementary base pairing between codon and anticodon when combined with the structure of the ribosome means that the amino acids will be joined together in the correct order to make the protein.
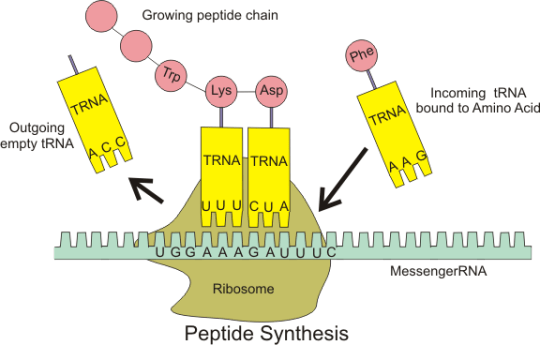
Please do not worry too much about the details of all this. I am sure that the examiners will not expect you to know the details of protein synthesis. But you should understand what an an anticodon is and the role of tRNA in the overall process.
anticodon: “a triplet of adjacent bases found on a transfer RNA molecule”
tRNA: “these molecules are found in the cytoplasm of cells and carry the correct amino acid into the ribosome. There is complementary base pairing between the codon on the mRNA and the anticodon on the tRNA as shown in the diagram above”
Protein Synthesis (part 2): Grade 9 Understanding for IGCSE Biology 3.18B
In the last post, I asked you to think of a good “2 mark” explanation of some important terms to do with protein synthesis. Here is my (GCSE level) answer…..
Gene: “a section of a DNA molecule that codes for the production of a single protein”
Ribosome: “a small structure found in the cytoplasm of cells where proteins are made by joining amino acids together into a long chain”
Transcription: “the process occurring in the nucleus in which a double-stranded DNA molecule is used to make a single-stranded molecule of messenger RNA”
Messenger RNA: ” a small single stranded molecule that is made in transcription and can carry the genetic information out of the nucleus to the ribosome”
Translation: “the second stage of protein synthesis that occurs in the cytoplasm in a ribosome in which amino acids are joined together in the correct order to make the protein”
Codon: “a triplet of adjacent bases in an mRNA molecule that codes for a single amino acid”
Finally I want to answer three important questions, one in this post, two in the next….
Why are codons three bases long?
Well, the answer here is a simple bit of Maths. If you remember, there are 20 possible amino acids that can be joined together in any order and in any number to make a protein. In DNA/RNA there are just four bases. So in order to code for 20 amino acids, how many “words” do you need? Well you need at least 20…..
In DNA/RNA you only have 4 “letters” available to make these words. (The letters are the bases and the words are the codons.)
- If the words were one letter long, there are only 4 words. (43 for the mathematicians): A,T,C,G
- If the words were two letters long, there are only 16 possible words (42 for the mathematicians): AA, AT, AC, AG, CA, CT, CC, CG, GA, GT, GC, GG, TA, TT, TC, TG
- If the words were three letters long, there are 64 possible words (43 for the mathematicians) AAA, AAT, AAC, AAG, ACA, ACT, ACC, ACG etc. etc.
So three bases in a codon is a minimum number needed to code for 20 different amino acids. But then this raises a question, doesn’t it? If there are 64 possible words and only 20 words needed, then what happens to all the extra, unnecessary codons? The answer is that there are lots of synonyms in the language of DNA/RNA. (Synonyms are two different words that have the same meaning)
Check out this picture of the genetic code (written in the language of RNA) and notice all the lovely synonyms!

Phe, Leu, Ser, Tyr, Cys and the others are names of amino acids
Notice that almost all amino acids have more than one codon that codes for them. For example, the amino acid Thr (threonine) is coded for by ACU, ACC, ACA and ACG in mRNA.
The three codons marked STOP are used as signals for the ribosome to stop the process of translation (but you don’t need to worry about that unless you wisely choose to continue your studies in Biology at A level!)
This is complicated stuff so please feel free to ask me questions about this using the “leave a comment” box below. You won’t get an instantaneous response but I try to check my blog every couple of days.
RNA: Grade 9 Understanding for IGCSE Biology 3.17B
You need to understand the structure of the molecule DNA before you read this post.
DNA stands for deoxyribonucleic acid and is the chemical that makes up the genetic information in all living organisms on earth. DNA is a double-stranded molecule in which each strand is made of a polymer of simple molecules called nucleotides. There are four nucleotides in DNA, with each nucleotide differing in the base present in the molecule. Adenine, Thymine, Cytosine and Thymine are the four bases found in the nucleotides in DNA. Every nucleotide in DNA contains the same sugar, deoxyribose and a phosphate group as shown in the diagram below.
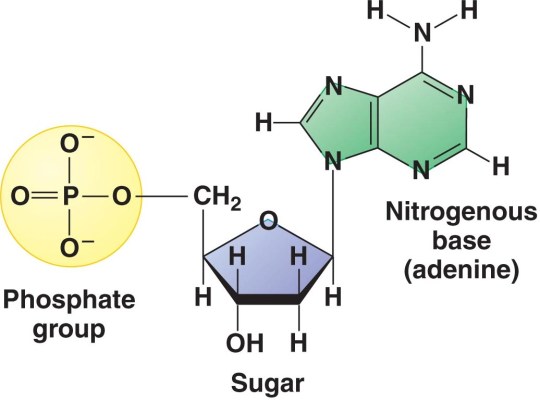
But DNA is not the only nucleic acid found in cells. All living cells also contain a similar molecule RNA that serves a whole variety of different functions. It is not the main genetic material in any cell but is essential in allowing the information contained in a DNA molecule to be expressed as a protein (see post on protein synthesis to come)
RNA stands for Ribonucleic Acid and is also a polymer of nucleotides. But whereas DNA is always a double-stranded molecule, RNA is always single-stranded (although certain forms of RNA can fold back on themselves at points so they can appear double stranded). The sugar in every RNA nucleotide is ribose (as opposed to deoxyribose in DNA).

There are also four different bases found in RNA nucleotides. Three are identical to the bases found in DNA (Adenine, Cytosine and Guanine) but there is no Thymine in RNA. RNA can contain nucleotides with the similar base Uracil in its place.

So in summary:
- RNA is single stranded whereas DNA is double stranded
- RNA contains the sugar ribose in every nucleotide whereas DNA contains deoxyribose
- DNA contains 4 bases (ATCG) whereas RNA contains A,U,C and G (thymine is replaced by uracil)
Protein Synthesis (part 1): Grade 9 Understanding for IGCSE Biology 3.18B
This is by far the most difficult concept for you to understand in the new GCSE specifications. In fact, it was only ever taught to A level students until last year (and to be honest I would much prefer it that way!). But that is no consolation to you poor folk who are going to get tested on it in your IGCSE and GCSE exams…
I am going to keep this as simple as I possibly can but am not going to dumb it down…. My blog is aimed for students who are ambitious to develop Grade 9 understanding in Biology (this topic is not tested at all in our Double Award Science course) so I want to explain it to you at the level you need. But you will need to read this carefully, take your time and you might need to break it down into small sections to build the understanding you need.
Can I suggest that first of all you read this post from my blog about DNA and how it works?
What is a gene?
A gene is a section of DNA that codes for a single protein. How does this code work? Well the short answer is that the sequence (order) of the bases as you read along the DNA molecule is a code for the sequence of amino acids that are joined together to make the protein.
Remember that there are 4 different bases in DNA: Adenine (A), Thymine (T), Cytosine (C) and Guanine (G). So a sequence of bases on a piece of DNA might look like this:
GCCTATAAATGGCAGGCATTAGCTCTAGGAAATCTAGGGACTTTACA
Protein Synthesis
Proteins are made by joining small molecules called amino acids together. This process is called protein synthesis and happens in small structures in the cytoplasm of all cells called ribosomes. But for all eukaryote cells, this poses a big geographical problem.
The “information” in the gene is stored in a sequence of bases in a DNA molecule and is found in the nucleus. DNA never leaves the nucleus because it is too important a molecule to be allowed into the reactive and unpredictable environment in the cytoplasm. But there are no ribosomes in the nucleus and these are the structures in which proteins are actually made. So a temporary intermediate molecule is needed to carry the “information” from the gene in the nucleus out into the cytoplasm where the ribosomes are found. So the process of making a protein therefore has to exist as a two stage process. The first stage is making the temporary intermediate molecule using the sequence of bases in the gene. Then there is a second stage that happens in the cytoplasm in the ribosome and this involves joining the amino acids together to make the actual protein.
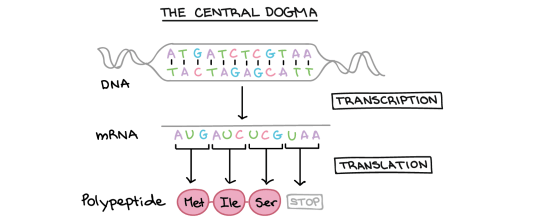
This idea was called the “central dogma of molecular biology” by Watson and Crick in their famous paper on the structure of DNA.

Transcription and Translation
There is quite a lot of jargon in this topic.
Transcription is the name for the process that happens in the nucleus in which a temporary intermediate molecule is made. This temporary “information-containing” molecule is a form of RNA called messenger RNA (or mRNA for short). The mRNA travels out of the nucleus to a ribosome which is found in the cytoplasm. Here a process called Translation occurs in which the the amino acids are joined together in the correct order to make the protein.
Look at this second diagram of the central dogma above. It shows a double-stranded DNA molecule at the top with pairs of bases (either A-T or C-G) joined by hydrogen bonds. The “information” in the molecule is found in the sequence of bases: on the top strand of the DNA this sequence is ATGATCTCGTAA.
You can see that transcription results in the formation of a molecule of mRNA. (Remember that RNA is always a single stranded molecule and contains the base Uracil in place of the base Thymine)
So can you see that the sequence of bases in the mRNA is almost identical to the DNA strand above, but with the base T replaced by the base U.
mRNA sequence: AUGAUCUCGUAA
This diagram shows us one final thing about how protein synthesis works. Look now at the small section of protein (polypeptide) that is produced in translation. You can see that this section of protein is made of three amino acids joined together: methionine (Met), attached to isoleucine (Ile) attached to serine (Ser)
Each amino acid is coded for by a group of 3 adjacent bases on the mRNA molecule. These triplets of bases are called Codons.
- AUG is a codon that codes for the amino acid Methionine
- AUC is a codon that codes for the amino acid Isoleucine
- UCG is a codon that codes for the amino acid Serine
(UAA is called a stop codon as it ends the translation process at the ribosome)
A codon is a triplet of adjacent bases on a mRNA molecule. Each codon codes for a single amino acid that will be joined together to make the protein.
Check your understanding:
Can you explain the meaning of the following terms? Write a 2 mark explanation of what each word means.
- Gene
- Ribosome
- Transcription
- Messenger RNA
- Translation
- Codon
I will put the answers into the next post called Protein Synthesis (part 2) which I promise I will write tomorrow…… That’s enough for now.

Fertilisers: Grade 9 understanding for IGCSE Biology 5.3
Fertilisers is the term used for “chemicals or natural substances added to soil to promote the growth of plants”.
Key point: in spite of what it says on this packet of fertiliser, fertilisers are not food for plants. (Just adding this photo to the post makes me feel slightly sick inside: how could MiracleGro be so happy to confuse generations of people who visit garden centres…..?)

Plants are autotrophic: they make their own food molecules in the amazing process of photosynthesis. Plants use carbon dioxide from the air plus water from their roots to produce a whole range of organic molecules powered by the energy from sunlight.
But remember that in order to make amino acids, proteins and DNA plants will also need a source of nitrogen atoms. Carbon dioxide and water do not contain any nitrogen atoms and yet nitrogen is needed for building amino acids, proteins and DNA.
Where do plants get this nitrogen from?
Well the key idea is that they do not take it from the air. Nitrogen gas in the air is very un-reactive and cannot be fixed in the plant. But the soil contains nitrate ions and plants can absorb these by active transport in their root hair cells. Nitrate ions are transported up the plant in the xylem and can be used to make amino acids etc. in the leaf cells.
Nitrates are not the only mineral ions taken up by plants in their roots. Plants absorb phosphate (for making DNA), magnesium (for making chlorophyll), potassium (for a wider variety of cellular processes) amongst many others.
So fertilisers are a way of replenishing the concentration of these essential minerals in the soil. More fertiliser, more minerals, faster plant growth as more proteins/DNA etc. can be made in the leaves…. Simples!

The commonest type of inorganic (chemical) fertiliser are called NPK fertilisers. (Nitrogen, Phosphate, Potassium). These can be bought in handy 50kg sacks (see picture above), stored and then spread easily over fields.
Farmers can also use manure which is an organic fertiliser. Here are some advantages/disadvantages of organic fertilisers in case you are interested…. It is smelly, bulky and difficult to store.

Cell division video: a revision video for DNA structure and chromosomes
This is a summary video that might help those of you still struggling to get to grips with chromosomes and genes. I apologise for the terribly amateur production values on the video but hope the biological content at least might be useful….

Chromosomes video – a short PMG summary of some important ideas for GCSE
This is my first attempt at making a short summary video as a follow up to lessons. I apologise for the poor sound in places – I hope the content makes sense. Please tweet or leave a reply with any questions.
Chromosomes: Grade 9 Understanding for IGCSE Biology 3.15 3.32
I hope everyone reading this blog knows the definition of a gene. It is one of the few things in the iGCSE course that it is worth learning by heart.
“A gene is a sequence of a DNA molecule that codes for a single protein“.
In human cells, every nucleus contains about 23,000 genes. Remember there is about 1.5m of DNA inside each nucleus. For most of the life-cycle of the cell, this DNA is in a tangled web called chromatin. Chromatin is DNA molecules loosely associated with some scaffolding proteins. The scaffolding proteins are shown in the second level down of this excellent diagram as “beads on a string”.
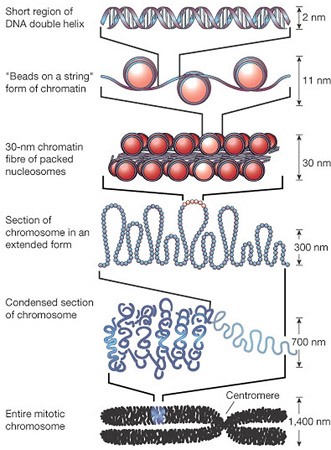
But this tangled web of DNA in chromatin poses a problem for the nucleus. For the cell to divide by mitosis, it is essential that the nucleus replicates into two identical nuclei, one for each new cell. The DNA molecules in the nucleus will make a copy of themselves by semi-conservative replication but how then can you ensure that each daughter nucleus gets exactly one copy of each DNA molecule if they are all tangled up….? This is where chromosomes come in!
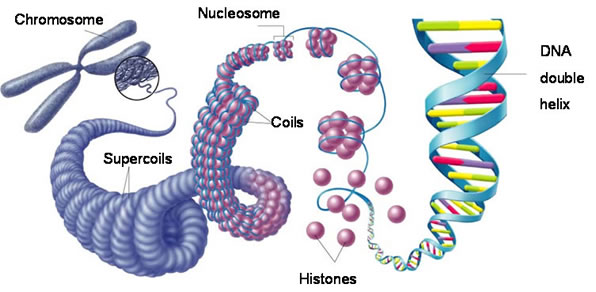
Each chromosome is a physical structure formed by supercoiling of the DNA round the scaffold proteins. The DNA coils, then folds back on itself, then coils again until each DNA molecule is so tightly coiled up that a visible chromosome appears in the nucleus. Chromosomes only become visible just before mitosis starts as for the rest of the time, the DNA is much more loosely coiled and so cannot be seen.
This also explains why each chromosome always looks X shaped. When chromosomes become visible the DNA has already replicated, so one chromosome is now made of two identical sister chromatids joined at a region called the centromere.

So the picture on the left shows a chromosome made as a single structure comprising one DNA molecule wrapped around the scaffold proteins. Then DNA replication occurs (in the S phase of the cell cycle) and now each chromosome is made of two identical chromatids joined at the centromere. Then the two chromatids are separated in mitosis and the chromosome returns to the structure it had at the start.
How many chromosomes are there in human cells?
The key idea here is that chromosomes are found in pairs in all body cells apart from gametes, These pairs of chromosomes (called homologous pairs) have exactly the same genes in the same locations on the chromosome. They are inherited one from each parent so one member of each pair will come from your father, one from your mother.
Different species have different numbers of pairs of chromosomes. For humans you should know that we have 23 pairs of chromosomes in the nucleus of every body cell (making a total of 46). Cells with chromosomes found in pairs are called diploid cells. Every cell in the body is diploid apart from the gametes. Gametes only have one member of each homologous pair and are called haploid cells.
Which of the following cells are diploid, which are haploid?
- Zygote
- Skin cell
- Sperm cell
- Liver cell
- Pollen grain
- Egg cell
If you are not sure, ask me by leaving a comment below….
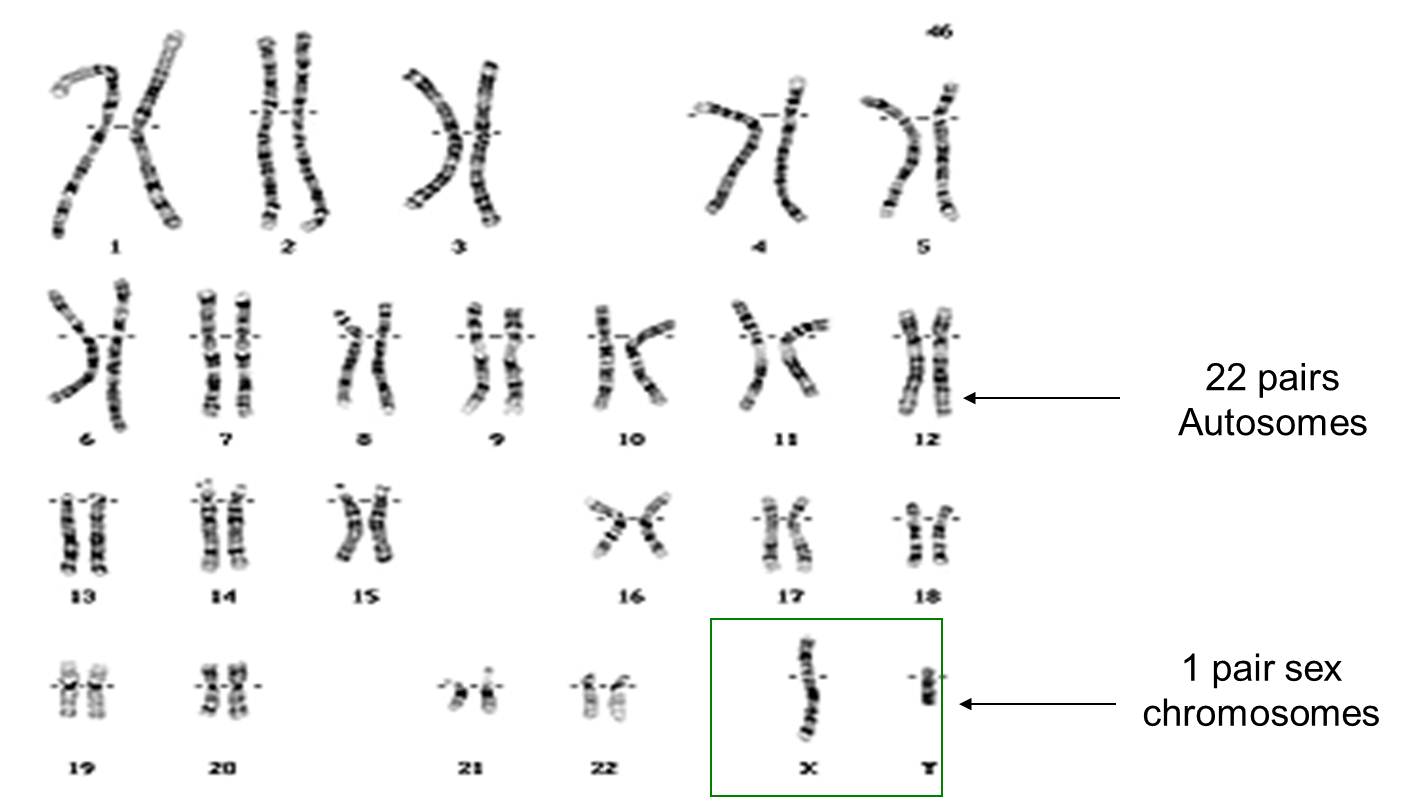
Finally for this post, chromosomes determine the sex of a human. You can see in the picture above that the 23 pairs of chromosomes can be divided into pairs 1 to 22 – these are called autosomes and play no role in determining your sex. But the 23rd pair of chromosomes are called the sex chromosomes. Males have one large X chromosome and one tiny Y chromosome as their 23rd pair whereas females have two large X chromosomes.
Gametes are haploid so only have one member of each pair. So when a man makes sperm cells (by meiosis) 50% of his sperm cells will contain his X chromosome, 50% his Y chromosome. A woman’s egg cell will always contain one X chromosome. (Why is this?) So I hope you can see that at the moment of fertilisation, the babies sex is determined depending on whether it is a Y-containing sperm cell that happens to fertilise the egg or an X-chromosome containing sperm… If the former, the baby is male, if the latter female.
I might explain this more fully in a post some other time….
Final thing for this post. If you have got to the end of this and understand everything in the text above, you are in a tiny minority of school students. Well done! This is a tricky topic and if you really understand chromosomes, you stand a chance of understanding cell division and genetics.
Summary video for Genes and Genetics
DNA video – a great summary for IGCSE Biologists
