
Tagged: gene
RNA: Grade 9 Understanding for IGCSE Biology 3.17B
You need to understand the structure of the molecule DNA before you read this post.
DNA stands for deoxyribonucleic acid and is the chemical that makes up the genetic information in all living organisms on earth. DNA is a double-stranded molecule in which each strand is made of a polymer of simple molecules called nucleotides. There are four nucleotides in DNA, with each nucleotide differing in the base present in the molecule. Adenine, Thymine, Cytosine and Thymine are the four bases found in the nucleotides in DNA. Every nucleotide in DNA contains the same sugar, deoxyribose and a phosphate group as shown in the diagram below.
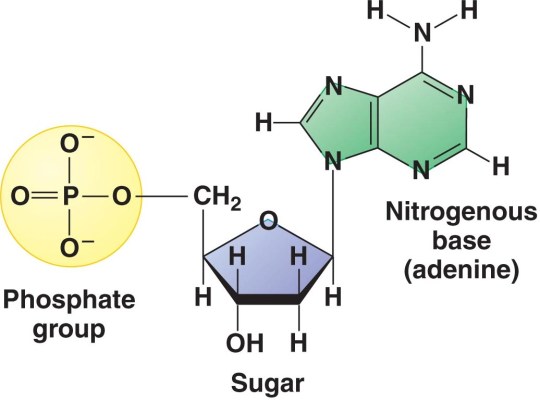
But DNA is not the only nucleic acid found in cells. All living cells also contain a similar molecule RNA that serves a whole variety of different functions. It is not the main genetic material in any cell but is essential in allowing the information contained in a DNA molecule to be expressed as a protein (see post on protein synthesis to come)
RNA stands for Ribonucleic Acid and is also a polymer of nucleotides. But whereas DNA is always a double-stranded molecule, RNA is always single-stranded (although certain forms of RNA can fold back on themselves at points so they can appear double stranded). The sugar in every RNA nucleotide is ribose (as opposed to deoxyribose in DNA).

There are also four different bases found in RNA nucleotides. Three are identical to the bases found in DNA (Adenine, Cytosine and Guanine) but there is no Thymine in RNA. RNA can contain nucleotides with the similar base Uracil in its place.

So in summary:
- RNA is single stranded whereas DNA is double stranded
- RNA contains the sugar ribose in every nucleotide whereas DNA contains deoxyribose
- DNA contains 4 bases (ATCG) whereas RNA contains A,U,C and G (thymine is replaced by uracil)
Protein Synthesis (part 1): Grade 9 Understanding for IGCSE Biology 3.18B
This is by far the most difficult concept for you to understand in the new GCSE specifications. In fact, it was only ever taught to A level students until last year (and to be honest I would much prefer it that way!). But that is no consolation to you poor folk who are going to get tested on it in your IGCSE and GCSE exams…
I am going to keep this as simple as I possibly can but am not going to dumb it down…. My blog is aimed for students who are ambitious to develop Grade 9 understanding in Biology (this topic is not tested at all in our Double Award Science course) so I want to explain it to you at the level you need. But you will need to read this carefully, take your time and you might need to break it down into small sections to build the understanding you need.
Can I suggest that first of all you read this post from my blog about DNA and how it works?
What is a gene?
A gene is a section of DNA that codes for a single protein. How does this code work? Well the short answer is that the sequence (order) of the bases as you read along the DNA molecule is a code for the sequence of amino acids that are joined together to make the protein.
Remember that there are 4 different bases in DNA: Adenine (A), Thymine (T), Cytosine (C) and Guanine (G). So a sequence of bases on a piece of DNA might look like this:
GCCTATAAATGGCAGGCATTAGCTCTAGGAAATCTAGGGACTTTACA
Protein Synthesis
Proteins are made by joining small molecules called amino acids together. This process is called protein synthesis and happens in small structures in the cytoplasm of all cells called ribosomes. But for all eukaryote cells, this poses a big geographical problem.
The “information” in the gene is stored in a sequence of bases in a DNA molecule and is found in the nucleus. DNA never leaves the nucleus because it is too important a molecule to be allowed into the reactive and unpredictable environment in the cytoplasm. But there are no ribosomes in the nucleus and these are the structures in which proteins are actually made. So a temporary intermediate molecule is needed to carry the “information” from the gene in the nucleus out into the cytoplasm where the ribosomes are found. So the process of making a protein therefore has to exist as a two stage process. The first stage is making the temporary intermediate molecule using the sequence of bases in the gene. Then there is a second stage that happens in the cytoplasm in the ribosome and this involves joining the amino acids together to make the actual protein.
This idea was called the “central dogma of molecular biology” by Watson and Crick in their famous paper on the structure of DNA.

Transcription and Translation
There is quite a lot of jargon in this topic.
Transcription is the name for the process that happens in the nucleus in which a temporary intermediate molecule is made. This temporary “information-containing” molecule is a form of RNA called messenger RNA (or mRNA for short). The mRNA travels out of the nucleus to a ribosome which is found in the cytoplasm. Here a process called Translation occurs in which the the amino acids are joined together in the correct order to make the protein.
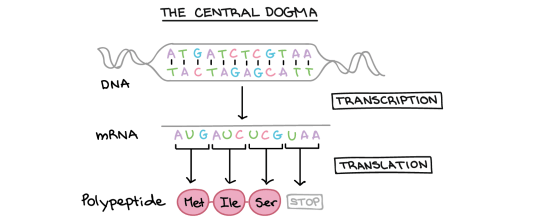
Look at this second diagram of the central dogma above. It shows a double-stranded DNA molecule at the top with pairs of bases (either A-T or C-G) joined by hydrogen bonds. The “information” in the molecule is found in the sequence of bases: on the top strand of the DNA this sequence is ATGATCTCGTAA.
You can see that transcription results in the formation of a molecule of mRNA. (Remember that RNA is always a single stranded molecule and contains the base Uracil in place of the base Thymine)
So can you see that the sequence of bases in the mRNA is almost identical to the DNA strand above, but with the base T replaced by the base U.
mRNA sequence: AUGAUCUCGUAA
This diagram shows us one final thing about how protein synthesis works. Look now at the small section of protein (polypeptide) that is produced in translation. You can see that this section of protein is made of three amino acids joined together: methionine (Met), attached to isoleucine (Ile) attached to serine (Ser)
Each amino acid is coded for by a group of 3 adjacent bases on the mRNA molecule. These triplets of bases are called Codons.
- AUG is a codon that codes for the amino acid Methionine
- AUC is a codon that codes for the amino acid Isoleucine
- UCG is a codon that codes for the amino acid Serine
(UAA is called a stop codon as it ends the translation process at the ribosome)
A codon is a triplet of adjacent bases on a mRNA molecule. Each codon codes for a single amino acid that will be joined together to make the protein.
Check your understanding:
Can you explain the meaning of the following terms? Write a 2 mark explanation of what each word means.
- Gene
- Ribosome
- Transcription
- Messenger RNA
- Translation
- Codon
I will put the answers into the next post called Protein Synthesis (part 2) which I promise I will write tomorrow…… That’s enough for now.
Cell division video: a revision video for DNA structure and chromosomes
This is a summary video that might help those of you still struggling to get to grips with chromosomes and genes. I apologise for the terribly amateur production values on the video but hope the biological content at least might be useful….
DNA video – a great summary for IGCSE Biologists
GFP fly
![en_GFP_fly3[1]](https://pmgbiology.com/wp-content/uploads/2015/05/en_gfp_fly31.jpg)
Just doing the pGLO practical this morning with my Y12 group and came across a great photo of a fly that has been genetically modified to express a gene from a species of Arctic jellyfish. The fly now makes a protein called GFP that causes it to flouresce green.

Three great Biology books to read over the Christmas holidays
It is one of the really good things about the extended curriculum at my school that students are not set work to do in the holidays. This allows time at home to be spent resting, recuperating and preparing for the term ahead. But can I make a suggestion as to what some of you might like to do before the start of next term? Find a really good book to read and read a chapter a day. Here are some personal suggestions as to some of my favourite Biology books.

“Genome” by Matt Ridley is a really interesting read. I have read it over and over again since it was first published in 2000. The chapters are short but the ideas contained within are important and challenging. The 23 chapters are each devoted to a single gene on a different human chromosome but Ridley is able to draw out some deep ideas with entertaining stories, anecdotes and superb detail. I would say this is ideal for either Y11 (D block) or Y12 (C Block) students.

Nick Lane came to Eton last year to speak to the Scientific and Banks Societies and he was about the best speaker we have had for a long time. This book is more suitable for Y12/13 students than GCSE readers as it has direct links to the pre-U course and contains some complex ideas. He is interested in the role mitochondria have played in the history of life and for me, Nick Lane is the best contemporary writer. If you like this, I can also recommend his later book “Life Ascending” which is also a super read.

This is my favourite Dawkins book. If you are interested in understanding the grand sweep of the tree of life and the history of life on our planet, there are a lot worse ways to start than reading this. Dawkins has a superb writing style and is able to make a complex chronology of species entertaining and easy to follow. If you do read any of these books and would like to tell me your thoughts, or indeed if you have other recommendations, please add a comment to this post so that others can see.
Happy Christmas!

Understanding Pedigrees: Grade 9 Genetics for IGCSE Biology 3.24
Sometimes genetics problems are based around a pedigree diagram. These diagrams show the phenotypes of individuals over several generations and allow deductions to be made about certain individuals phenotypes. Often pedigrees are used to show the inheritance of a particular disease in a family.

You can see that circles in the pedigree represent females, squares represent males. If the symbol is filled in, then the person suffers from the disease. Empty symbols represent people who do not have the disease.
Have a look at the pedigree above? What does this tell you about the disease?
Well the first and most obvious thing is that this disease is caused by a recessive allele, h.
If you see two people who don’t have the disease producing one or more children who do, then this must be a genetic disease caused by a recessive allele. In the top generation, parents 1 and 2 do not have the disease, but they have three children 2,3,4 one of whom has the disease.
What does this tell us about the genotype of parents 1 and 2 in generation I? Well if neither have the disease and they have a child who does, both 1 and 2 in the top generation must be heterozygous – Hh
Anyone with the disease must be homozygous recessive hh.
Have a look at generation II in the diagram above?
The man, number 2, who is a sufferer and so genotype hh marries woman 1 who does not have the disease. They produce 4 children, three with the disease and one without. What must the genotype of the woman 1 be? Well she must be heterozygous Hh. How do we know? What children would she produce if she were a homozygous HH woman?

A pedigree caused by a dominant allele would look very different. Every sufferer would have at least one parent who also suffers from the disease. Two sufferers producing some children who do not have the disease is indicative of a disease caused by a dominant allele. If we use the symbol P for the dominant allele that causes the disease, and p for the recessive allele that is “normal”, can you work out the genotypes of all 12 people on the diagram above?
- Pp
- Pp
- pp
- Pp
- PP or Pp
- PP or Pp
- pp
- pp
- Pp
- pp
- pp
- pp

Grade 9 GCSE Genetics: avoid a common error in understanding at IGCSE 3.19
There are one or two things which make a biology teacher’s (and indeed an exam marker’s) blood pressure rise. Well in fact in my case there are many dozens of things, as some of you know, but let’s keep it to the things candidates write in genetics answers in exams. This post is an attempt to encourage you to avoid the commonest “howler”.
The dominant allele does not have to be the more common one in a population.
Just because an allele is dominant, it does not mean it will be the most common in a population. I often hear answers in which people think that in a population 3/4 of the population will have the dominant phenotype, 1/4 will be recessive. This is utter nonsense of course. The ratio of 3:1 only applies to the probabilities of offspring produced by mating two heterozygous individuals.
There is a gene in humans in which a mutation can cause polydactyly: this rare condition results in babies born with an extra digit on each hand. Anne Boleyn was a famous sufferer in the past. But the allele of the gene that causes polydactyly is dominant – it is a P allele. I would imagine everyone reading this post, (all 12 of you…..), will probably have the genotype pp. The p allele that causes a normal hand to form is very very common in our population whereas the P allele is very very rare.
Don’t ever believe that just because an allele is common, it must be dominant.

How to score full marks on a genetics question in IGCSE Biology? 3.20, 3.23, 3.25
Few things in life are certain, famously just death and taxes. Northampton Town flirting with relegation can perhaps be added to this list. But you can be pretty certain that tucked away somewhere in your iGCSE Biology exam there will be a genetics question that asks you to draw a genetic diagram. There are usually four or even five marks available and so learning how to ensure you get all these marks is vital in your quest for an A* grade.
GCSE candidates are terrible at doing genetic diagrams: they fill the space with messy scribbles, doodles, strange tables and lines and then confidently write 3:1 at the bottom… Not a recipe for success. So learn how to do it, be neat, take your time and you can guarantee full marks.
If the question doesn’t do it for you, you should start by defining what the letters you will use for the alleles. If one allele is dominant over the other, it is conventional to use the upper case letter for the dominant allele, the lower case letter for the recessive one. It will tell you in the question which allele is dominant.
Start your genetic diagram by writing the phenotype of the parents in the cross.
e.g. Parental Phenotype: Tall Tall
Underneath the phenotype, write the genotype of the parents.
Parental Genotype: Tt Tt
Then you need to think about which alleles are present in the gametes. Gametes are haploid and so will contain one of each pair of homologous chromosomes – in this example there can only be one allele in each gamete (as we are only looking at one gene)
Gametes: T t T t
Next show random fertilisation. I think it is much better to draw a Punnett square that has the male gametes down one side, the female gametes down the other and then carefully pair them up. This is a stage where mistakes can be made if you rush so however simple you think this process is, take your time…..
Random Fertilisation
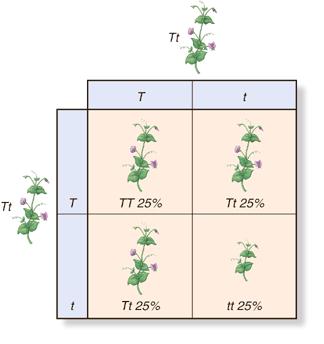
Finally you need to copy out the offspring genotypes from your Punnet square, like so
Offspring Genotypes: TT Tt Tt tt
And underneath each one, write the offspring phenotype
Offspring Phenotypes: Tall Tall Tall Dwarf
Finally, answer the question. If it asks for a probability, express your answer as either a percentage or a decimal or a fraction. So if I were asked what is the probability of a homozygous pea being produced, the answer is 50% or 0.5 or 1/2
Follow these rules and you will always score full marks – happy days……..

Genetics jargon: Grade 9 Understanding for IGCSE Biology 3.20
The science of genetics looks at how inherited characteristics are passed from one generation to the next. The father of genetics was the Moravian monk, Gregor Mendel, who showed with his breeding experiments in peas that individual, discrete “particles” are passed from one generation to the next. We now know that these “particles” are actually small sections of a DNA molecule called genes.
Mendel worked out that there were always two such “particles” in any cell which acted together to determine the feature described. But he knew that gametes (sex cells such as pollen grains and egg cells) only contained one “particle” for each feature. You should understand why this is.
The discrete particles that are passed from generation to generation are genes: these are sections of a DNA molecule and are located on chromosomes. Chromosomes in most organisms are found in pairs within the nucleus of a cell. The word for a cell that contains pairs of homologous chromosomes is a diploid. The gametes do not have pairs of chromosomes: they are haploid cells that contain one member of each pair. This ensures that at fertilisation when two gametes fuse, a diploid zygote is produced.
iGCSE candidates can find genetics a difficult topic and one reason is that there is lots of jargon. Have a look at my definitions for these jargon words and ensure that you understand what they mean. Genetics is not a topic in which rote learning and memorisation are helpful – the very top candidates at iGCSE will understand what is going on, and can then answer all possible questions with ease.
Gene: ” a section of a DNA molecule that codes for a single protein”
Allele: “an alternative version of a gene found at the same gene locus”
Gene locus: “the place on a chromosome where a particular gene is found”
Phenotype: “the appearance of an organism, e.g tall, short, blue eyes etc.”
Genotype: “the combination of alleles at a single gene locus that an organism possesses – e.g TT, Tt”
Homozygous: “a gene locus where the two alleles are identical is said to be homozygous – e.g. TT, tt”
Heterozygous: “a gene locus where the two alleles are different is heterozygous – e.g. Tt”
Dominant allele: “a dominant allele is the one that determines the phenotype in a heterozygous individual”
Recessive allele: ” a recessive allele can only determine the phenotype in a homozygous individual”
Codominance: “two alleles are codominant if they both contribute to the phenotype in a heterozygous individual”
