Tagged: protein
Protein Synthesis (part 2): Grade 9 Understanding for IGCSE Biology 3.18B
In the last post, I asked you to think of a good “2 mark” explanation of some important terms to do with protein synthesis. Here is my (GCSE level) answer…..
Gene: “a section of a DNA molecule that codes for the production of a single protein”
Ribosome: “a small structure found in the cytoplasm of cells where proteins are made by joining amino acids together into a long chain”
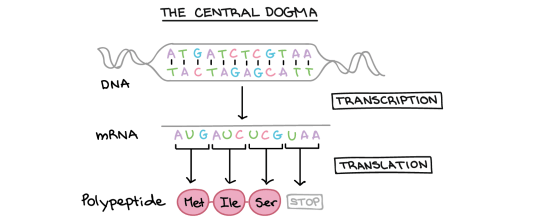
Transcription: “the process occurring in the nucleus in which a double-stranded DNA molecule is used to make a single-stranded molecule of messenger RNA”
Messenger RNA: ” a small single stranded molecule that is made in transcription and can carry the genetic information out of the nucleus to the ribosome”
Translation: “the second stage of protein synthesis that occurs in the cytoplasm in a ribosome in which amino acids are joined together in the correct order to make the protein”
Codon: “a triplet of adjacent bases in an mRNA molecule that codes for a single amino acid”
Finally I want to answer three important questions, one in this post, two in the next….
Why are codons three bases long?
Well, the answer here is a simple bit of Maths. If you remember, there are 20 possible amino acids that can be joined together in any order and in any number to make a protein. In DNA/RNA there are just four bases. So in order to code for 20 amino acids, how many “words” do you need? Well you need at least 20…..
In DNA/RNA you only have 4 “letters” available to make these words. (The letters are the bases and the words are the codons.)
- If the words were one letter long, there are only 4 words. (43 for the mathematicians): A,T,C,G
- If the words were two letters long, there are only 16 possible words (42 for the mathematicians): AA, AT, AC, AG, CA, CT, CC, CG, GA, GT, GC, GG, TA, TT, TC, TG
- If the words were three letters long, there are 64 possible words (43 for the mathematicians) AAA, AAT, AAC, AAG, ACA, ACT, ACC, ACG etc. etc.
So three bases in a codon is a minimum number needed to code for 20 different amino acids. But then this raises a question, doesn’t it? If there are 64 possible words and only 20 words needed, then what happens to all the extra, unnecessary codons? The answer is that there are lots of synonyms in the language of DNA/RNA. (Synonyms are two different words that have the same meaning)
Check out this picture of the genetic code (written in the language of RNA) and notice all the lovely synonyms!

Phe, Leu, Ser, Tyr, Cys and the others are names of amino acids
Notice that almost all amino acids have more than one codon that codes for them. For example, the amino acid Thr (threonine) is coded for by ACU, ACC, ACA and ACG in mRNA.
The three codons marked STOP are used as signals for the ribosome to stop the process of translation (but you don’t need to worry about that unless you wisely choose to continue your studies in Biology at A level!)
This is complicated stuff so please feel free to ask me questions about this using the “leave a comment” box below. You won’t get an instantaneous response but I try to check my blog every couple of days.

Digestion of Proteins: Grade 9 Understanding for IGCSE Biology 2.29
Proteins are large insoluble molecules made up of many hundreds of amino acids joined together in a long chain. So in order to obtain these molecules from our diet, the large protein must be digested (broken down) into the smaller amino acid subunits. Amino acids can be absorbed into the blood stream in the ileum, part of the small intestine.
The family of enzymes that can catalyst the digestion of proteins are called proteases.
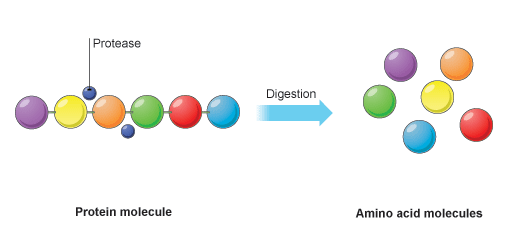
Protein digestion happens in a two-stage process. In the first stage the large protein molecules are broken down into smaller proteins (often called polypeptides) by a protease enzyme. Pepsin is one such protease and acts in the stomach.
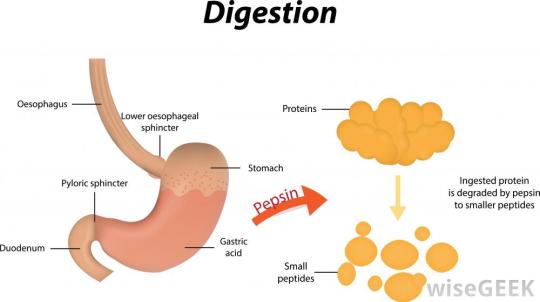
Remember that the food in the stomach is mixed with hydrochloric acid. This results in a very acidic liquid in the stomach (chyme). Pepsin works in the stomach and so rather unusually for a digestive enzyme, it has an optimum pH of pH 1.5 – pH2.
The second protease enzyme that you should know about is trypsin. Trypsin is made in the pancreas and so enters the duodenum soon after the stomach contents pass the pyloric sphincter (see diagram above). The acidic chyme that enters the duodenum is rapidly neutralised by hydrogencarbonate ions (an alkali) secreted in the bile and in pancreatic juice. Trypsin has an optimum pH of around pH 7.5.
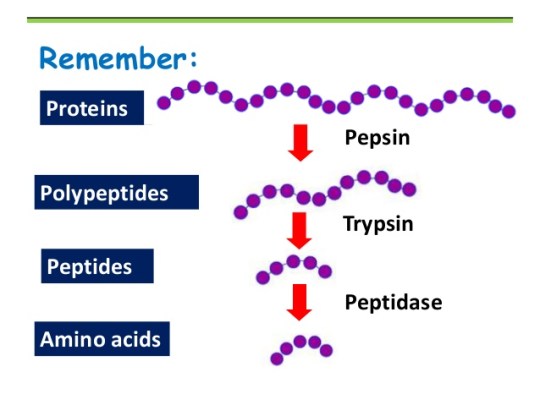
As shown in the diagram above, there is a final stage to protein digestion. The actions of pepsin in the stomach and trypsin the duodenum result in small protein fragments called peptides. Many peptides are still too large to be absorbed into the blood in the ileum and so need digesting further into their constituent amino acids. Peptidase enzymes are embedded in the epithelial cell membranes in the small intestine and this final reaction completes the digestion of proteins.
Amino acids are absorbed by active transport into the blood capillaries in the villi in the small intestine.

Human Diet: Grade 9 Understanding for IGCSE Biology 2.24
All animals are heterotrophic. This means that they cannot make their own food molecules but need to get them from some external source. Humans get a variety of different food molecules from what they eat. Diet is a term for what an animal eats (and in a biological context has no associations with any attempt to lose weight or change body shape). A balanced diet is a combination of foods that provides the correct proportions of all the various food molecules for any particular individual at any particular stage of their life.
Components of a Balanced Diet
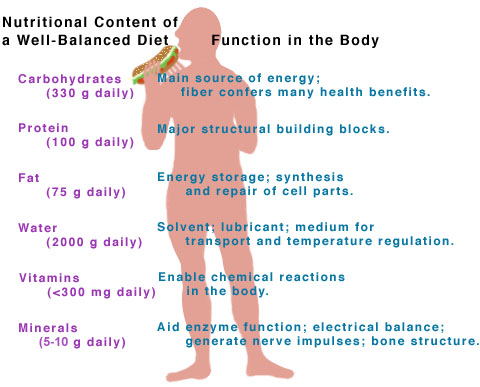
Carbohydrates
Carbohydrates are a family of molecules that includes sugars, starch and other polysaccharides. They contain C,H and O atoms only and their main function in the diet is to provide molecules that can be respired to release energy for cells. Carbohydrates are thus one of the main respiratory substrates in our diet. All sweet foods will contain sugars of course and starch-rich foods are vegetables like potatoes, pasta and rice. Starch is a polymer of glucose and so needs to be digested to glucose because it is too large a molecule to be absorbed in the small intestine.
Protein
Proteins are a family of macromolecules needed to build new cells and thus for growth. Like starch, Proteins are also polymers and thus get digested into their constituent monomers, in this case amino acids in the digestive system. Protein-rich foods include all meat and some pulses and beans. Proteins in the diet are needed to build muscle tissue, to form some components of cell membranes and to make all the enzymes that catalyse all the metabolic reactions in cells.
Lipids
Lipid is a general term for all fats and oils. Despite the popular misconception that fat is “bad” in our diet, in fact lipids are essential molecules in the diet. We need lipids as a respiratory substrate, for long term energy storage in adipose tissue under the skin and for the electrical insulation of nerve cells. Foods rich in lipids are red meat, many processed foods, and food containing olive oil or other vegetable oils.
Minerals
Humans need a wide variety of mineral ions in very low concentrations in our diet. The most important mineral in our diet is Calcium which is needed for making healthy teeth and bones. Iron is also needed in relatively high amounts as it is required to make the protein haemoglobin found in red blood cells. Mineral ions come from eating a wide variety of foods, but the main source of calcium is from milk and other dairy products. Iron is found in high concentrations in red meat. 
Vitamins
Rather like minerals, vitamins are needed in very small amounts in a diet but are absolutely crucial for the healthy functioning of the body. The diseases associated with a lack of a particular vitamin in the diet are called deficiency diseases. You need to know about three vitamins – A. C and D  Vitamin A is a molecule called retinal found in carrots, red peppers and swede. It is needed for healthy growth and a functioning immune system. Vitamin A is also essential for normal vision since it is used to make the pigment found in rod cells in the retina. Vitamin A deficiency in the diet often causes poor vision, especially at night. Vitamin C is needed for the enzyme that produces the protein collagen in the body. It is found in all fruit especially citrus fruits. A lack of vitamin C causes the deficiency disease scurvy. Vitamin D is an unusual vitamin since it can be made in the skin using UV light. Vitamin D is needed in the small intestine to absorb mineral ions such as calcium, magnesium, etc. into the blood. A lack of vitamin D often results in a deficiency disease called rickets in which the bones malform.
Vitamin A is a molecule called retinal found in carrots, red peppers and swede. It is needed for healthy growth and a functioning immune system. Vitamin A is also essential for normal vision since it is used to make the pigment found in rod cells in the retina. Vitamin A deficiency in the diet often causes poor vision, especially at night. Vitamin C is needed for the enzyme that produces the protein collagen in the body. It is found in all fruit especially citrus fruits. A lack of vitamin C causes the deficiency disease scurvy. Vitamin D is an unusual vitamin since it can be made in the skin using UV light. Vitamin D is needed in the small intestine to absorb mineral ions such as calcium, magnesium, etc. into the blood. A lack of vitamin D often results in a deficiency disease called rickets in which the bones malform. 
Fibre
Dietary Fibre is actually made up from the molecule cellulose. No mammal including humans possesses a cellulase enzyme and so when plant material passes through the intestines, dietary fibre is never digested. This means it passes into the large intestine where it helps prevent constipation. Foods rich in fibre included wholegrain bread, vegetables and some breakfast cereals.
Water
Water is the final component of a balanced diet. It is needed to replace water lost by sweating and in urine and acts as a solvent of course for all the metabolic reactions that happen in every cell.

Diffusion, Active Transport and Osmosis: Grade 9 Understanding for IGCSE Biology 2.15 2.16
This post is going to describe some of the ways molecules can cross the cell membrane. (For Eton students revising for Trials, diffusion and active transport are found in the F block syllabus, osmosis comes in E Block)
Diffusion is the simplest to understand. Diffusion does not even need a cell membrane to occur. In the example below the dye molecules will move randomly in the solution. As the dye starts in one place, these random movements will mean that slowly spread out until an equilibrium is reached. This movement of the dye from the region of high concentration to the low concentration is called diffusion.

When considering diffusion into a cell, if the cell membrane is permeable to a particular molecule then the random movements of the molecule will mean that there will be a net (overall) movement from the higher concentration to the lower concentration down the concentration gradient.

Key Points about diffusion:
- Always happens down a concentration gradient (from a high concentration to a lower one)
- Never requires any energy from the cell – it is a passive process
Active Transport is a process that will move molecules into a cell against the concentration gradient – i.e. from a low concentration to a high concentration. This “pumping” of the molecules against the gradient requires energy from the cell and of course this energy comes from respiration.

You can see from the diagram above that active transport is working against the concentration gradient, is using energy from inside the cell (actually a molecule made in mitochondria in respiration called ATP) and that a specific transport protein is involved in the cell membrane. This protein will have a binding-site that is specific for a particular molecule and the solute molecule to be transported will collide with the transport protein due to random movement. Energy from the cell can cause the transport protein to change shape such that the solute is released on the other side of the membrane.
Can you think of another area of the iGCSE syllabus which features collisions between a specific binding-site on a protein and a certain other molecule? Linking ideas is a key characteristic of the A* Biologist!

Osmosis is the hardest of these processes to understand properly, especially as an iGCSE student when you are often told an over-simplified account that does not make sense…. Let’s try to simplify it in a way that does make sense.
Firstly it is only water molecules that can move by osmosis into and out of cells – never anything else. Indeed osmosis is the only way water can cross a membrane – it never moves by diffusion or active transport.
Osmosis is a passive process – it never needs any energy from the cell’s respiration and the only energy involved is the kinetic energy of the water molecules.
Osmosis can only occur through a partially permeable membrane. All cell membranes are partially permeable and this means they let small molecule like water through but prevent the diffusion of the larger solute molecules.

The water molecules on both sides of the membrane in the diagram above will be moving around randomly. They will occasionally hit one of the pores in the membrane and so pass across the membrane. This movement will be happening from left to right and from right to left.
But….
The presence of the sucrose (solute) in the solution on the right means that some of the water molecules on that side of the membrane are less able to move. This is because they are temporarily attracted to the solute molecules by weak hydrogen bonds. So their kinetic energy is reduced and this makes them less likely to randomly collide with the pores in the membrane. The presence of the solute on the right means that water molecules on the left on average are more likely to collide with the membrane than the water molecules on the right and this leads to an overall movement from left to right. This net movement of water molecules from the dilute solution to the more concentrated solution through the partially permeable membrane is called osmosis.

This diagram has the two solutions reversed so in which direction will osmosis happen here? Thats right from right to left. You can see the hydrogen bonds attracting water molecules to the solute – these are the ones that lower their kinetic energy overall.
You might even have been taught about osmosis with reference to the water potential of a solution. The water potential of a solution is just a measure of how much kinetic energy the water molecules in a solution possess. So a dilute solution will have a high water potential, a concentrated solution (with lots of dissolved solute) a lower water potential.
Osmosis is the
- net movement of water
- through a partially permeable membrane
- from a solution with a high water potential (a dilute solution) to a solution with a lower water potential (a concentrated solution)
Biological examples
Diffusion
- Oxygen diffuses from the air in the alveolus into the blood
- Carbon Dioxide diffuses from the air spaces in the leaf into the palisade mesophyll cells of the leaf
- Glucose diffuses from the blood into an actively-respiring muscle
Active Transport
- Nitrates are pumped from the soil into root hair cells by active transport
- In the kidney, glucose and other useful molecules are pumped from the nephron back into the blood by active transport.
- In nerve cells, sodium and potassium ions are pumped across the cell membrane to set up the gradients needed for a nerve impulse
Osmosis
- Water enters root hair cells from the soil by osmosis
- In the kidney, water is reabsorbed from the nephron by osmosis.
- In the large intestine, water is reabsorbed from the colon back into the blood by osmosis
There are many many more examples of each process, but this should be enough to be going on with…….

What does DNA do? – Grade 9 Understanding for IGCSE Biology 3.14 3.15
In my previous post, I explained the structure of the molecule DNA. DNA is a long polymer found in the nucleus of all eukaryotic cells. But understanding the structure of the molecule is not too difficult… At iGCSE level it is quite hard to understand what DNA does in the cell and why it is such an important molecule in Biology. This post is an attempt to explain this more complex idea. Here goes…..
DNA is a molecule that can store information
This is a tricky concept to understand. You learn that the genetic information in a cell is stored in the nucleus but what does this phrase actually mean? Well I think it makes sense if you start to think of DNA is being a language. Consider the English language for a minute. How is information stored in this language? Well if you see the word CAT in English, you learn that these three letters in this order with a space either side conveys a meaning. The meaning is a small domesticated mammal of the family Felidae famous for their selfish temperament and willingness to kill huge numbers of wild song birds and rodents.

So a sequence of letters in English can form a word that has a distinct meaning.
Well there are sequences of letters in a DNA molecule too. The molecule is made up of two long chains of nucleotides joined together. There are four different nucleotides in DNA that differ in the base they contain – either Adenine (A), Thymine (T), Cytosine (C) or Guanine (G). So you could represent one half of the DNA molecule by a sequence of letters, like this: AGGCTACCCGTTATGCGTATC
(Remember that the opposite strand of a DNA molecule will always have complementary bases in the same sequence: in this case TCCGATGGGCAATACGCATAG)
The information in a DNA molecule is found by reading along one strand of the double helix. The sequence of bases as you read along the molecule can convey information in the same way as sequences of letters in English convey information.
Differences between English language and the language of DNA:
- English language has 26 letters, DNA has just four
- Words in English can have different lengths, in DNA all words are just three letters long.
There are others but lets leave it at that just for the moment…..
You might like to think how many words are possible in a language made up of 4 letters with each word being three letters long.
What information is stored in DNA?
DNA contains the information needed to build proteins. Proteins are a different kind of biological polymer made up of long chains of amino acids. There are 20 different kinds of amino acid that can be joined together to make a protein and as proteins can be several hundred amino acid residues long, the mathematically confident among you will see that the potential number of different proteins is enormous.
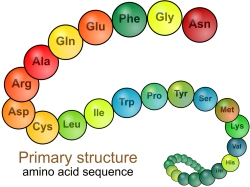
This wide variety of different possible structures of proteins is what makes them such important molecules in cells. The different protein molecules will all have different shapes and this means they can do a wide variety of different tasks in the cell.
What do proteins do in cells?
- Enzymes (catalysing all metabolic reactions)
- Transport Proteins (e.g for active transport)
- Structural Proteins (e.g. the proteins that make up the spindle in cell division)
- Contractile Proteins (essential in muscle cells)
- etc. etc. etc.
What information does the cell need to make a protein? Well it only really needs to know what sequence to join together the amino acids in to make up a protein. And this is what DNA does… The sequence of bases in the DNA as you read along one strand is a code that tells the cell the sequence of amino acids to join together to make a protein.
Each word in DNA is a called a codon and is three bases long. You should have calculated earlier that there are 64 codons (words) in the language of DNA. Don’t worry about the details of this table, but here is a picture that shows the 64 codons in DAN and the amino acid they code for: Phe, Leu, Val etc. are abbreviations of the names of amino acids.
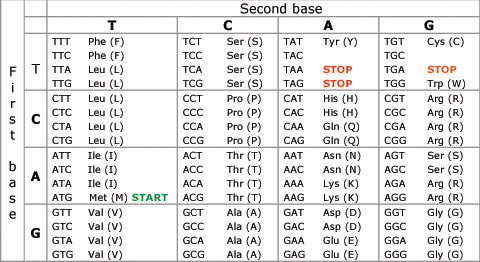
So if CAT in English means a small furry mouse killer, CAT in the language of DNA means join the amino acid Histidine at this point in the growing protein chain.
DNA has another trick up its sleeve (it really is a special molecule……)
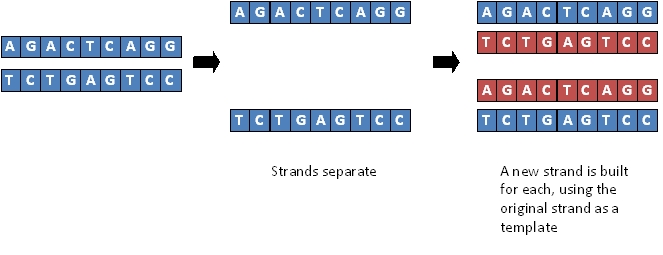
As well as being a brilliant coding molecule for storing information (see above) DNA is also a self-replicating molecule. This means that it can make a copy of itself very easily. You don’t need to worry how DNA moelcules are copied but you can probably see how it is done. Indeed Watson and Crick worked it out once they understood the double helix structure of the molecule…..
If you can “unzip” the DNA molecule by breaking the hydrogen bonds that hold the base pairs together, each strand can be used as a template for building a new complementary molecule. (Do you understand what complementary means in this context? If not, look it up! It is nothing to do with being nice to each other…..)