Tagged: 3.14
Chromosomes: Grade 9 Understanding for IGCSE Biology 3.15 3.32
I hope everyone reading this blog knows the definition of a gene. It is one of the few things in the iGCSE course that it is worth learning by heart.
“A gene is a sequence of a DNA molecule that codes for a single protein“.
In human cells, every nucleus contains about 23,000 genes. Remember there is about 1.5m of DNA inside each nucleus. For most of the life-cycle of the cell, this DNA is in a tangled web called chromatin. Chromatin is DNA molecules loosely associated with some scaffolding proteins. The scaffolding proteins are shown in the second level down of this excellent diagram as “beads on a string”.
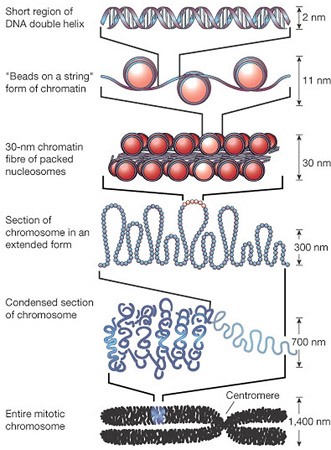
But this tangled web of DNA in chromatin poses a problem for the nucleus. For the cell to divide by mitosis, it is essential that the nucleus replicates into two identical nuclei, one for each new cell. The DNA molecules in the nucleus will make a copy of themselves by semi-conservative replication but how then can you ensure that each daughter nucleus gets exactly one copy of each DNA molecule if they are all tangled up….? This is where chromosomes come in!
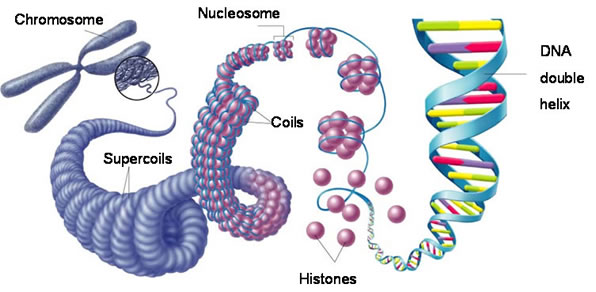
Each chromosome is a physical structure formed by supercoiling of the DNA round the scaffold proteins. The DNA coils, then folds back on itself, then coils again until each DNA molecule is so tightly coiled up that a visible chromosome appears in the nucleus. Chromosomes only become visible just before mitosis starts as for the rest of the time, the DNA is much more loosely coiled and so cannot be seen.
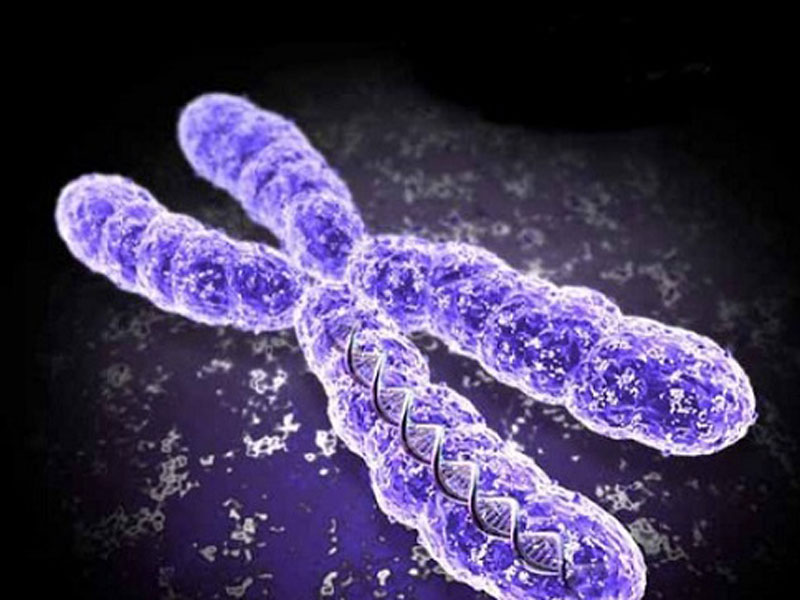
This also explains why each chromosome always looks X shaped. When chromosomes become visible the DNA has already replicated, so one chromosome is now made of two identical sister chromatids joined at a region called the centromere.

So the picture on the left shows a chromosome made as a single structure comprising one DNA molecule wrapped around the scaffold proteins. Then DNA replication occurs (in the S phase of the cell cycle) and now each chromosome is made of two identical chromatids joined at the centromere. Then the two chromatids are separated in mitosis and the chromosome returns to the structure it had at the start.
How many chromosomes are there in human cells?
The key idea here is that chromosomes are found in pairs in all body cells apart from gametes, These pairs of chromosomes (called homologous pairs) have exactly the same genes in the same locations on the chromosome. They are inherited one from each parent so one member of each pair will come from your father, one from your mother.
Different species have different numbers of pairs of chromosomes. For humans you should know that we have 23 pairs of chromosomes in the nucleus of every body cell (making a total of 46). Cells with chromosomes found in pairs are called diploid cells. Every cell in the body is diploid apart from the gametes. Gametes only have one member of each homologous pair and are called haploid cells.
Which of the following cells are diploid, which are haploid?
- Zygote
- Skin cell
- Sperm cell
- Liver cell
- Pollen grain
- Egg cell
If you are not sure, ask me by leaving a comment below….
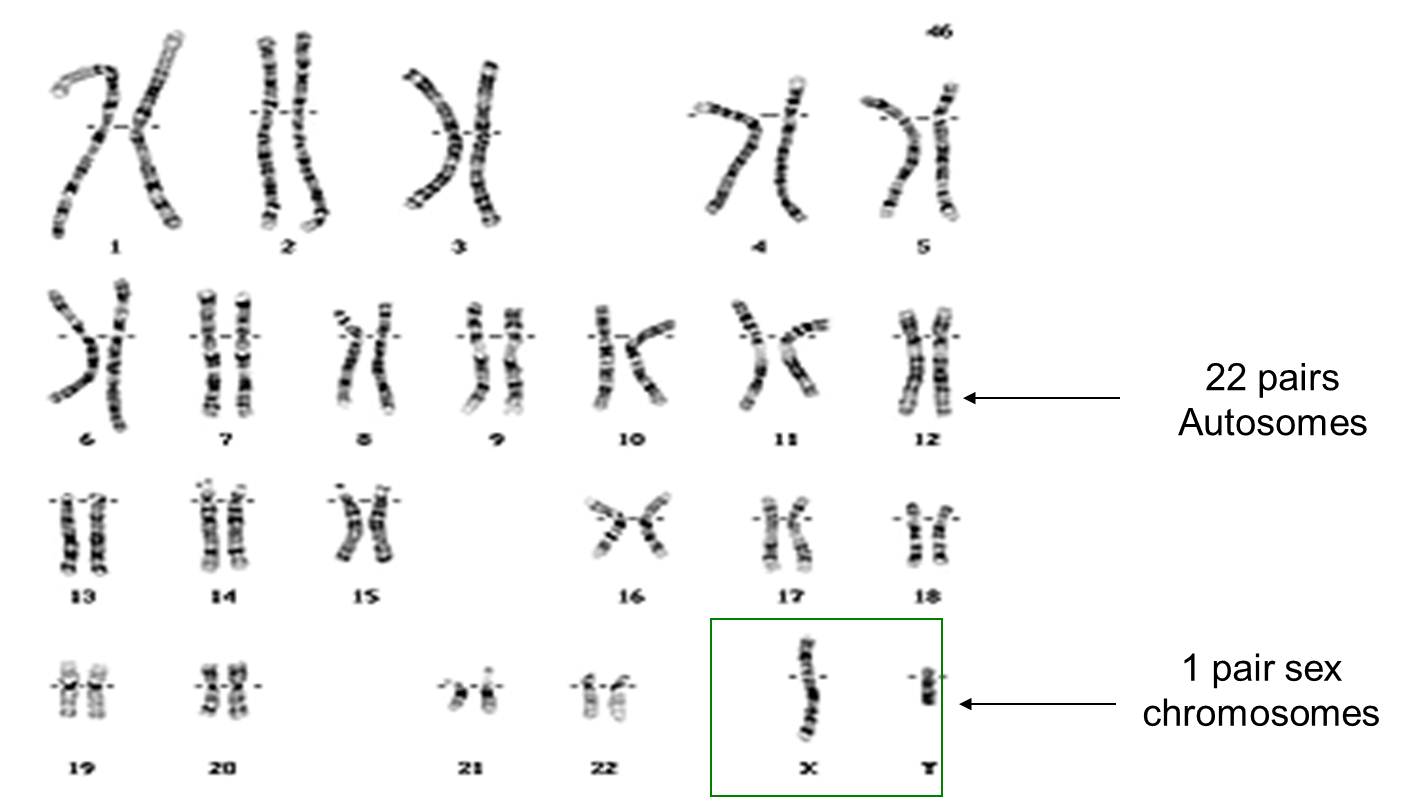
Finally for this post, chromosomes determine the sex of a human. You can see in the picture above that the 23 pairs of chromosomes can be divided into pairs 1 to 22 – these are called autosomes and play no role in determining your sex. But the 23rd pair of chromosomes are called the sex chromosomes. Males have one large X chromosome and one tiny Y chromosome as their 23rd pair whereas females have two large X chromosomes.
Gametes are haploid so only have one member of each pair. So when a man makes sperm cells (by meiosis) 50% of his sperm cells will contain his X chromosome, 50% his Y chromosome. A woman’s egg cell will always contain one X chromosome. (Why is this?) So I hope you can see that at the moment of fertilisation, the babies sex is determined depending on whether it is a Y-containing sperm cell that happens to fertilise the egg or an X-chromosome containing sperm… If the former, the baby is male, if the latter female.
I might explain this more fully in a post some other time….
Final thing for this post. If you have got to the end of this and understand everything in the text above, you are in a tiny minority of school students. Well done! This is a tricky topic and if you really understand chromosomes, you stand a chance of understanding cell division and genetics.

What does DNA do? – Grade 9 Understanding for IGCSE Biology 3.14 3.15
In my previous post, I explained the structure of the molecule DNA. DNA is a long polymer found in the nucleus of all eukaryotic cells. But understanding the structure of the molecule is not too difficult… At iGCSE level it is quite hard to understand what DNA does in the cell and why it is such an important molecule in Biology. This post is an attempt to explain this more complex idea. Here goes…..
DNA is a molecule that can store information
This is a tricky concept to understand. You learn that the genetic information in a cell is stored in the nucleus but what does this phrase actually mean? Well I think it makes sense if you start to think of DNA is being a language. Consider the English language for a minute. How is information stored in this language? Well if you see the word CAT in English, you learn that these three letters in this order with a space either side conveys a meaning. The meaning is a small domesticated mammal of the family Felidae famous for their selfish temperament and willingness to kill huge numbers of wild song birds and rodents.

So a sequence of letters in English can form a word that has a distinct meaning.
Well there are sequences of letters in a DNA molecule too. The molecule is made up of two long chains of nucleotides joined together. There are four different nucleotides in DNA that differ in the base they contain – either Adenine (A), Thymine (T), Cytosine (C) or Guanine (G). So you could represent one half of the DNA molecule by a sequence of letters, like this: AGGCTACCCGTTATGCGTATC
(Remember that the opposite strand of a DNA molecule will always have complementary bases in the same sequence: in this case TCCGATGGGCAATACGCATAG)
The information in a DNA molecule is found by reading along one strand of the double helix. The sequence of bases as you read along the molecule can convey information in the same way as sequences of letters in English convey information.
Differences between English language and the language of DNA:
- English language has 26 letters, DNA has just four
- Words in English can have different lengths, in DNA all words are just three letters long.
There are others but lets leave it at that just for the moment…..
You might like to think how many words are possible in a language made up of 4 letters with each word being three letters long.
What information is stored in DNA?
DNA contains the information needed to build proteins. Proteins are a different kind of biological polymer made up of long chains of amino acids. There are 20 different kinds of amino acid that can be joined together to make a protein and as proteins can be several hundred amino acid residues long, the mathematically confident among you will see that the potential number of different proteins is enormous.
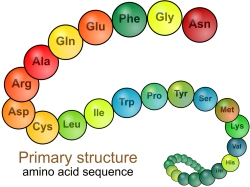
This wide variety of different possible structures of proteins is what makes them such important molecules in cells. The different protein molecules will all have different shapes and this means they can do a wide variety of different tasks in the cell.
What do proteins do in cells?
- Enzymes (catalysing all metabolic reactions)
- Transport Proteins (e.g for active transport)
- Structural Proteins (e.g. the proteins that make up the spindle in cell division)
- Contractile Proteins (essential in muscle cells)
- etc. etc. etc.
What information does the cell need to make a protein? Well it only really needs to know what sequence to join together the amino acids in to make up a protein. And this is what DNA does… The sequence of bases in the DNA as you read along one strand is a code that tells the cell the sequence of amino acids to join together to make a protein.
Each word in DNA is a called a codon and is three bases long. You should have calculated earlier that there are 64 codons (words) in the language of DNA. Don’t worry about the details of this table, but here is a picture that shows the 64 codons in DAN and the amino acid they code for: Phe, Leu, Val etc. are abbreviations of the names of amino acids.
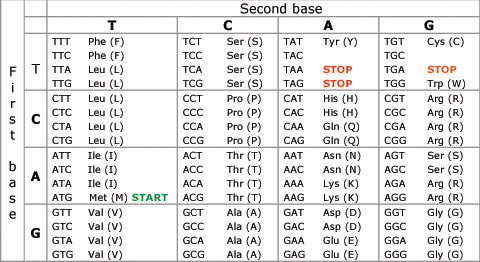
So if CAT in English means a small furry mouse killer, CAT in the language of DNA means join the amino acid Histidine at this point in the growing protein chain.
DNA has another trick up its sleeve (it really is a special molecule……)
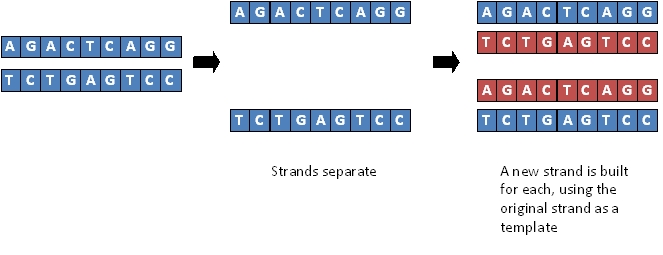
As well as being a brilliant coding molecule for storing information (see above) DNA is also a self-replicating molecule. This means that it can make a copy of itself very easily. You don’t need to worry how DNA moelcules are copied but you can probably see how it is done. Indeed Watson and Crick worked it out once they understood the double helix structure of the molecule…..
If you can “unzip” the DNA molecule by breaking the hydrogen bonds that hold the base pairs together, each strand can be used as a template for building a new complementary molecule. (Do you understand what complementary means in this context? If not, look it up! It is nothing to do with being nice to each other…..)
DNA structure and function – IGCSE Grade 9 Understanding 3.16B
I have been working today on making a video to explain DNA structure, chromosomes and cell division to post on YouTube. This has proved harder than I anticipated (not just because I look ridiculous and keep stuttering….) but I hope there may be something for you by lunchtime tomorrow….
So I will have to resort to the more old-fashioned medium of the blog. (The times they are a’changing)
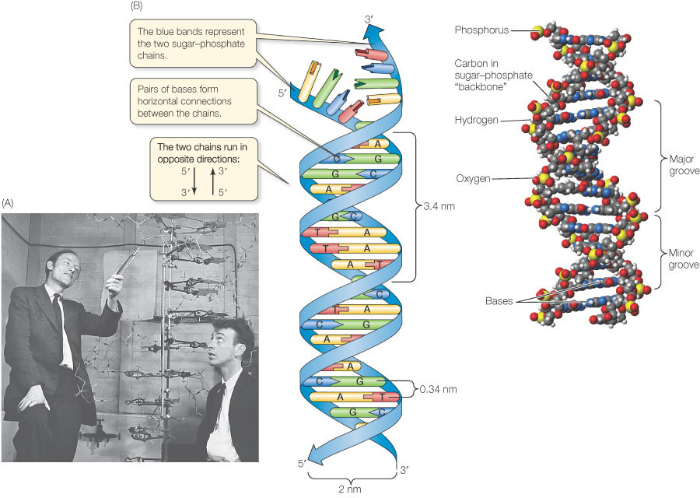
Firstly DNA is from the family of molecules called Nucleic Acids. These are examples of biological polymers (macromolecules) and you should know that a polymer is a large molecule made of a chain of repeating subunits.

The monomers that make up a DNA molecule are called nucleotides. A single nucleotide is made up of a phosphate group attached to the sugar, deoxyribose which in turn is attached to a nitrogenous (nitrogen-containing) base.

Every nucleotide in DNA has the same phosphate group, the same sugar (deoxyribose) but there are four alternative bases in DNA nucleotides. You don’t need to worry about the structure of these four bases but you do need to know their names: Adenine, Guanine, Cytosine and Thymine.
Now the next idea is that a single DNA molecule is actually made up of two chains of nucleotides joined together. These two polynucleotide chains line up alongside one another and are held together by hydrogen bonds between the pairs of bases in the middle of the molecule. There are two antiparallel sugar-phosophate backbones on the outside and the pairs of bases in the middle. You can see that the bases always pair together in a predictable way. A pairs with T (joined by two hydrogen bonds) and C pairs with G (joined by three hydrogen bonds)
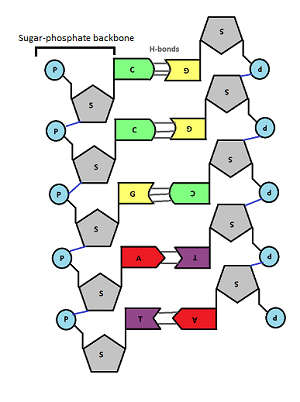
Can you see why the two strands that make up the DNA molecule are described as being antiparallel?
There are only two more things to appreciate about the structure of the molecule DNA:
Firstly it is appreciating how long the actual DNA molecule might be. The diagram above shows a structure 5 base pairs in length. The DNA molecules in the nuclei of your cells might be hundreds of millions of base pairs in length. If you look at the sum total in a single human nucleus there are DNA molecules 3 billion base pairs long – a molecule that if allowed to line up in a straight line would extend to around 2 metres in length.
And finally the fact about the structure of DNA that everyone remembers – it is a double helix. The two sugar-phosphate backbones do not run in a straight line as in the diagram above but coil around each other into the infamous double helix.