RNA: Grade 9 Understanding for IGCSE Biology 3.17B
You need to understand the structure of the molecule DNA before you read this post.
DNA stands for deoxyribonucleic acid and is the chemical that makes up the genetic information in all living organisms on earth. DNA is a double-stranded molecule in which each strand is made of a polymer of simple molecules called nucleotides. There are four nucleotides in DNA, with each nucleotide differing in the base present in the molecule. Adenine, Thymine, Cytosine and Thymine are the four bases found in the nucleotides in DNA. Every nucleotide in DNA contains the same sugar, deoxyribose and a phosphate group as shown in the diagram below.
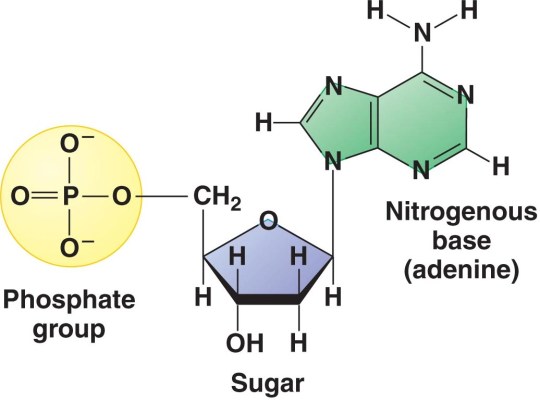
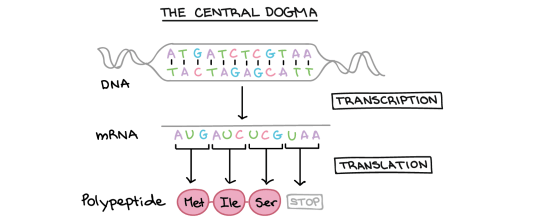
But DNA is not the only nucleic acid found in cells. All living cells also contain a similar molecule RNA that serves a whole variety of different functions. It is not the main genetic material in any cell but is essential in allowing the information contained in a DNA molecule to be expressed as a protein (see post on protein synthesis to come)
RNA stands for Ribonucleic Acid and is also a polymer of nucleotides. But whereas DNA is always a double-stranded molecule, RNA is always single-stranded (although certain forms of RNA can fold back on themselves at points so they can appear double stranded). The sugar in every RNA nucleotide is ribose (as opposed to deoxyribose in DNA).

There are also four different bases found in RNA nucleotides. Three are identical to the bases found in DNA (Adenine, Cytosine and Guanine) but there is no Thymine in RNA. RNA can contain nucleotides with the similar base Uracil in its place.

So in summary:
- RNA is single stranded whereas DNA is double stranded
- RNA contains the sugar ribose in every nucleotide whereas DNA contains deoxyribose
- DNA contains 4 bases (ATCG) whereas RNA contains A,U,C and G (thymine is replaced by uracil)