The World is Changing – 2011 video showing our changing planet

Most of the work you do on transport in plants concerns the movement of water and minerals from the roots to the leaves of the plants in xylem vessels. (see previous post on xylem transport) You should understand what transpiration is, and how the properties of water allow a transpiration pull provide the energy to move large volumes of water up the xylem in the plant.
But what about the second plant transport tissue phloem? How does it differ from xylem in both structure and function?
Well structurally the tissues are very different. Xylem vessels are large, dead, empty thick-walled cells with cell walls strengthened with lignin. The transport cells in phloem are called sieve-tubes. Phloem sieve tubes are living cells with thin cell walls.

In xylem vessels the end walls break down completely but in phloem sieve tubes, the end walls are filled with many holes forming a structure called a sieve plate. Each phloem sieve tube has a smaller cell called a companion cell alongside and both these two cells must be alive for phloem transport to occur.

What is transported in phloem sieve tubes?
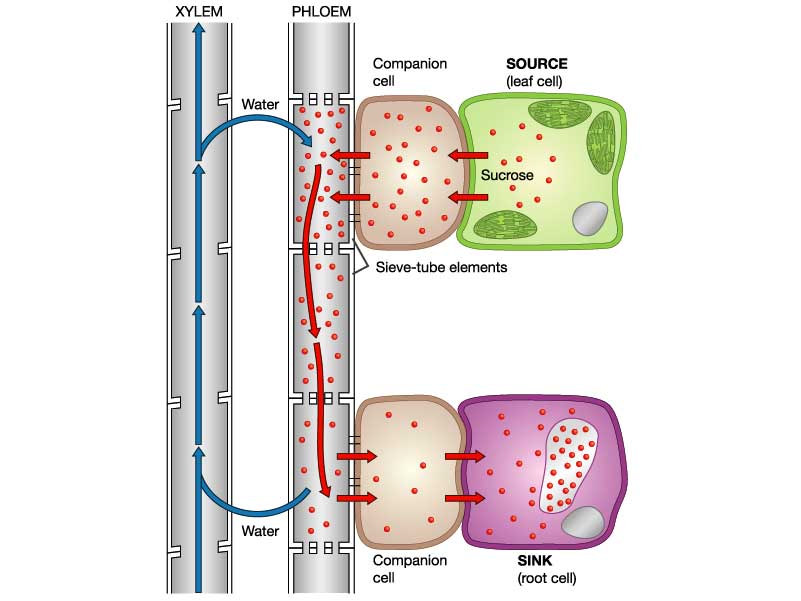
Plants transport the products of photosynthesis (food molecules) up and down the stem in phloem. The main carbohydrate transported is sucrose but phloem cells also contain lots of amino acids and a few other sugars.
The mechanism by which these sugars are moved around the plant is less well understood than for water movement in xylem. Translocation is an active process and requires energy from respiration in the cells. It is possible that a bulk flow exists as shown in the diagram below, but this mechanism cannot be the whole story….. Can you think why? Post a comment if you want to explain some of the difficulties with this theory…..

You should understand how bacteria can be genetically modified to produce useful proteins (e.g.human insulin, human growth hormone, vaccine antigens etc.) – see previous post if you are unsure. In this post, I will try to explain how transgenic plants can be made and indeed what kind of genes might be added to plants to benefit humans. Genetically modifying a plant will be a more complex process since plants are multicellular and so many millions of cells need to be genetically altered.
Luckily a vector exists that can transfer genes into many varieties of plant. Agrobacterium tumefaciens is a species of bacterium that contains a plasmid that can be transferred into plant cells. This plasmid (called the Ti plasmid) can be cut open with a restriction enzyme and a new gene inserted with DNA ligase.
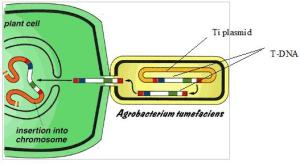
The Agrobacterium that have been genetically modified will then infect the plant tissue and then when this plant tissue is cultivated using the micropropagation techniques you learned about with cauliflower, a whole GM plant can be produced.


Genes can also be inserted into plants by a gene gun. A gene gun literally fires “bullets” made of tiny particles of gold that have been coated with the required DNA and while Agrobacterium does not infect all species of plant, the gene gun can work to get foreign DNA into any plant species.
What are the potential advantages of GM crops?

Resistance to Herbicide: some crop plants have been altered so they contain a gene that makes them resistant to a particular herbicide. This means a farmer can spray the herbicide on his crop without risk of harming the crop plant.
Resistance to Frost: some GM plants have a gene from a species of Arctic fish that codes for an “antifreeze” chemical in the fish blood. Plants that contain this gene will be frost-resistant and so produce can be transported in refrigerated containers without damaging the plant cells.
Golden Rice: rice plants have been altered so they contain genes that make the molecule beta-carotene. This is the orange pigment found in carrots and is a precursor for making vitamin A. So in populations who rely on rice as a staple component of their diet, the rice will be more nutritious and so prevent the night-blindness associated with vitamin A deficiency.
Antibody production: plants may also be genetically modified to produce antibodies for treatment of human disease.



In the last post on this topic, I explained about the two types of enzymes needed for the genetic modification of organisms:
Restriction enzymes that can cut up DNA molecules at specific target sequences, often resulting in fragments with sticky ends
DNA ligase that joins together fragments to form a single DNA molecule
The EdExcel iGCSE syllabus uses the example of the genetic modification of bacteria to produce human insulin. Human insulin is a hormone that helps regulate the concentration of glucose in the blood. It is made in the pancreas when the blood glucose concentration gets too high and causes liver cells to take up glucose from the blood and convert it to the storage molecule glycogen. Patients with type I diabetes cannot make their own insulin and so need to inject it several times a day after meals to ensure they maintain a constant healthy concentration of glucose in their blood.
Bacteria can be genetically modified so that they produce human insulin. These transgenic bacteria can be cultured in a fermenter and the insulin produced can be extracted, purified and sold.
How do you get hold of the human insulin gene?
Well the honest answer is that there are a variety of ways of achieving this. It can now be synthesised artificially as we know the exact base sequence of the gene but it can also be cut out of a human DNA library using a restriction enzyme. There are other ways too but for the sake of brevity (and sanity) I am not going to go into them here. [If you are really interested in this, find out how reverse transcription of messenger RNA from cells in the pancreas can allow you to build the insulin gene.]
How do you get the human insulin gene into a bacterium?
Remember that bacterial cells are fundamentally different to animal and plant cells. One difference is that bacterial cells have no nucleus and their DNA is in the form of a ring that floats in the cytoplasm. Many bacteria also have plasmids which are small additional rings of DNA and these provide a way for getting a new gene into a bacterium.

Bacteria exchange plasmids in a process called conjugation and so it is fairly easy to get the plasmid out of the bacterium. If the plasmid is cut open using the same restriction enzyme as was used to cut out the human insulin gene, the sticky ends will match up and so DNA ligase will join the two pieces of DNA together to make a recombinant plasmid. The diagram below shows the process for human growth hormone but it would be exactly the same for the example we are looking at.
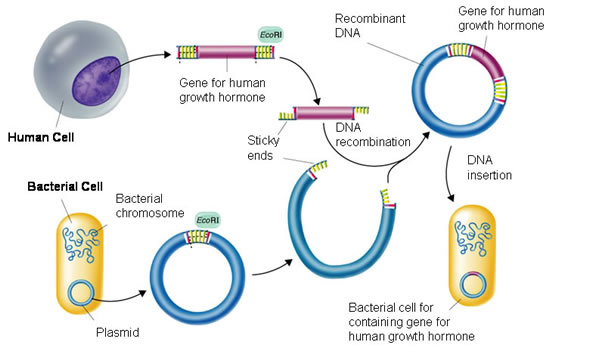
If the recombinant plasmids are inserted into bacteria, the bacteria will read the human insulin gene and so produce the protein insulin.

How do you grow the transgenic bacteria on an industrial scale?
The bacteria that have taken up the recombinant plasmid are grown in a fermenter. This is a large stainless steel vat (easy to clean and sterilise) that often has several design features conserved between different varieties:

The fermenter usually has a cooling jacket to carry away excess heat. The jacket often has a cold water input pipe and the warmer water is carried away. There has to be some mechanism for mixing the contents of the fermenter so the diagram above shows paddles attached to a motor. Fermenters also need a sterile input system for getting air, water and nutrients into the fermenter but without introducing foreign bacteria and fungi. Air is needed as the bacteria are aerobic and need oxygen for respiration.

If the bacteria in the fermenter contain the human insulin gene, then they will be able to produce human insulin. This can be extracted, purified and sold to the NHS for treating type I diabetics.

One of the most complicated areas in the iGCSE course is looking at how organisms can be genetically modified. Remember that humans have been messing around with the genetic composition of many species for thousands of years. Up until recently this has only been using a technique called selective breeding or artificial selection.
Make sure you understand exactly what is meant by the term selective breeding? You probably should be able to explain at least one example in both an animal and a plant species.
In the twentieth century scientists developed a much more precise way of genetically modifying a species. This was due to discoveries about the nature of the genetic code and also the existence of two types of enzyme that make cutting up and then sticking together pieces of DNA. This new technique was called genetic engineering and it has two big advantages over selective breeding. Firstly genes from different species can be recombined to form transgenic organisms. Transgenic is an important term and means an organism that contains DNA from more than one species. This means scientists are not restricted to alleles present in the natural population but can insert genes from any species into any other. Secondly, selective breeding has a big disadvantage in that it can reduce the allelic diversity in a population. If the population becomes more and more similar at a genetic level, this means that inbreeding becomes more of a problem and the population becomes susceptible to damage from changes in the environment.
You need to understand the role of two enzymes in the process of Genetic Engineering:
Restriction Enzymes are found in bacteria and have evolved to combat viral infection in the bacterial cell. These enzymes can cut double-stranded DNA at a specific target sequence, often leaving the ends of the DNA with short sections of unpaired bases. These are called sticky ends.
The image below shows the cutting site of a restriction enzyme called EcoR1. You can see the enzyme cuts the DNA anywhere the following sequence is found GAATTC. The DNA molecule is cut after the first G, leaving the two strands with four unpaired bases that make up the two sticky ends.
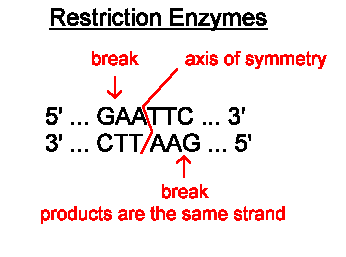
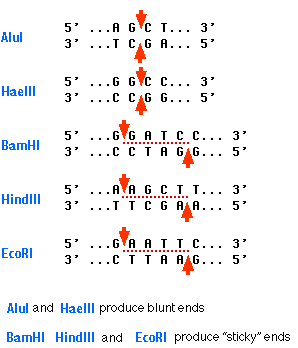
Here are some more restriction enzymes and there target sequences. The bottom three on the list all produce sticky ends.
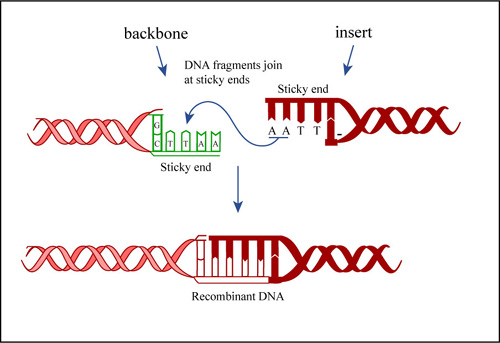
The second important enzyme for genetic engineering is DNA Ligase. This enzyme catalyses the joining together of the sticky ends of two fragments to produce an intact DNA molecule.
The starting point for understanding the complex topic of genetic modification of organisms is understanding the role of these two enzymes in the process.


In my previous post, I explained the structure of the molecule DNA. DNA is a long polymer found in the nucleus of all eukaryotic cells. But understanding the structure of the molecule is not too difficult… At iGCSE level it is quite hard to understand what DNA does in the cell and why it is such an important molecule in Biology. This post is an attempt to explain this more complex idea. Here goes…..
DNA is a molecule that can store information
This is a tricky concept to understand. You learn that the genetic information in a cell is stored in the nucleus but what does this phrase actually mean? Well I think it makes sense if you start to think of DNA is being a language. Consider the English language for a minute. How is information stored in this language? Well if you see the word CAT in English, you learn that these three letters in this order with a space either side conveys a meaning. The meaning is a small domesticated mammal of the family Felidae famous for their selfish temperament and willingness to kill huge numbers of wild song birds and rodents.

So a sequence of letters in English can form a word that has a distinct meaning.
Well there are sequences of letters in a DNA molecule too. The molecule is made up of two long chains of nucleotides joined together. There are four different nucleotides in DNA that differ in the base they contain – either Adenine (A), Thymine (T), Cytosine (C) or Guanine (G). So you could represent one half of the DNA molecule by a sequence of letters, like this: AGGCTACCCGTTATGCGTATC
(Remember that the opposite strand of a DNA molecule will always have complementary bases in the same sequence: in this case TCCGATGGGCAATACGCATAG)
The information in a DNA molecule is found by reading along one strand of the double helix. The sequence of bases as you read along the molecule can convey information in the same way as sequences of letters in English convey information.
Differences between English language and the language of DNA:
There are others but lets leave it at that just for the moment…..
You might like to think how many words are possible in a language made up of 4 letters with each word being three letters long.
What information is stored in DNA?
DNA contains the information needed to build proteins. Proteins are a different kind of biological polymer made up of long chains of amino acids. There are 20 different kinds of amino acid that can be joined together to make a protein and as proteins can be several hundred amino acid residues long, the mathematically confident among you will see that the potential number of different proteins is enormous.
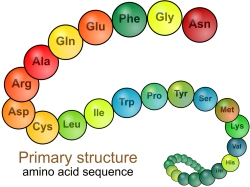
This wide variety of different possible structures of proteins is what makes them such important molecules in cells. The different protein molecules will all have different shapes and this means they can do a wide variety of different tasks in the cell.
What do proteins do in cells?
What information does the cell need to make a protein? Well it only really needs to know what sequence to join together the amino acids in to make up a protein. And this is what DNA does… The sequence of bases in the DNA as you read along one strand is a code that tells the cell the sequence of amino acids to join together to make a protein.
Each word in DNA is a called a codon and is three bases long. You should have calculated earlier that there are 64 codons (words) in the language of DNA. Don’t worry about the details of this table, but here is a picture that shows the 64 codons in DAN and the amino acid they code for: Phe, Leu, Val etc. are abbreviations of the names of amino acids.
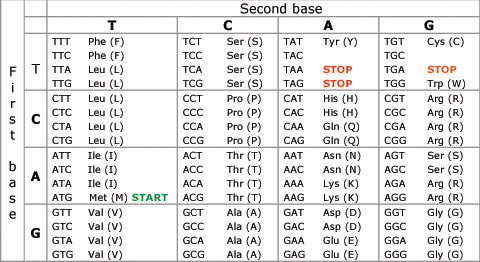
So if CAT in English means a small furry mouse killer, CAT in the language of DNA means join the amino acid Histidine at this point in the growing protein chain.
DNA has another trick up its sleeve (it really is a special molecule……)
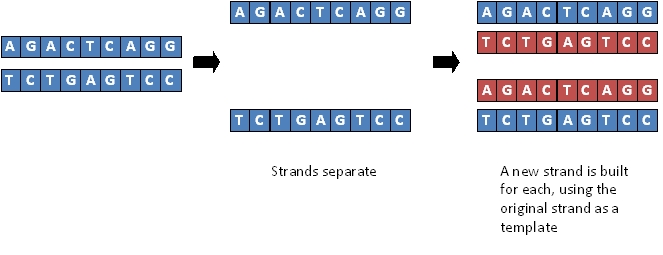
As well as being a brilliant coding molecule for storing information (see above) DNA is also a self-replicating molecule. This means that it can make a copy of itself very easily. You don’t need to worry how DNA moelcules are copied but you can probably see how it is done. Indeed Watson and Crick worked it out once they understood the double helix structure of the molecule…..
If you can “unzip” the DNA molecule by breaking the hydrogen bonds that hold the base pairs together, each strand can be used as a template for building a new complementary molecule. (Do you understand what complementary means in this context? If not, look it up! It is nothing to do with being nice to each other…..)
I have been working today on making a video to explain DNA structure, chromosomes and cell division to post on YouTube. This has proved harder than I anticipated (not just because I look ridiculous and keep stuttering….) but I hope there may be something for you by lunchtime tomorrow….
So I will have to resort to the more old-fashioned medium of the blog. (The times they are a’changing)
Firstly DNA is from the family of molecules called Nucleic Acids. These are examples of biological polymers (macromolecules) and you should know that a polymer is a large molecule made of a chain of repeating subunits.

The monomers that make up a DNA molecule are called nucleotides. A single nucleotide is made up of a phosphate group attached to the sugar, deoxyribose which in turn is attached to a nitrogenous (nitrogen-containing) base.

Every nucleotide in DNA has the same phosphate group, the same sugar (deoxyribose) but there are four alternative bases in DNA nucleotides. You don’t need to worry about the structure of these four bases but you do need to know their names: Adenine, Guanine, Cytosine and Thymine.
Now the next idea is that a single DNA molecule is actually made up of two chains of nucleotides joined together. These two polynucleotide chains line up alongside one another and are held together by hydrogen bonds between the pairs of bases in the middle of the molecule. There are two antiparallel sugar-phosophate backbones on the outside and the pairs of bases in the middle. You can see that the bases always pair together in a predictable way. A pairs with T (joined by two hydrogen bonds) and C pairs with G (joined by three hydrogen bonds)
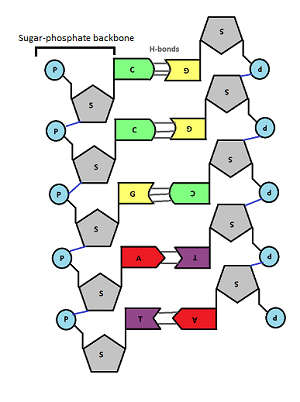
Can you see why the two strands that make up the DNA molecule are described as being antiparallel?
There are only two more things to appreciate about the structure of the molecule DNA:
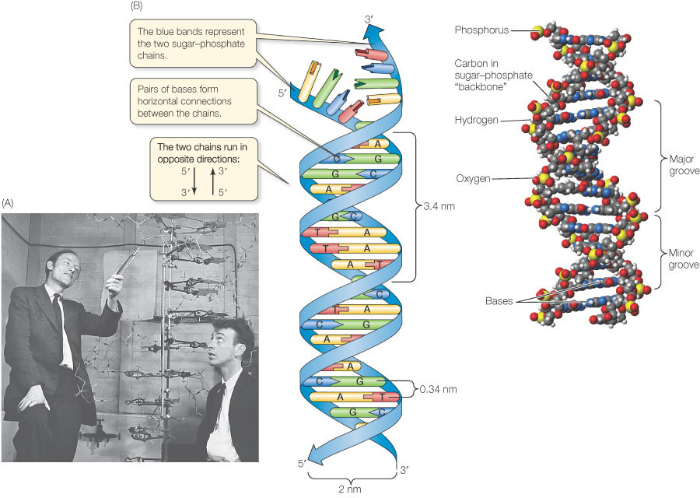
Firstly it is appreciating how long the actual DNA molecule might be. The diagram above shows a structure 5 base pairs in length. The DNA molecules in the nuclei of your cells might be hundreds of millions of base pairs in length. If you look at the sum total in a single human nucleus there are DNA molecules 3 billion base pairs long – a molecule that if allowed to line up in a straight line would extend to around 2 metres in length.
And finally the fact about the structure of DNA that everyone remembers – it is a double helix. The two sugar-phosphate backbones do not run in a straight line as in the diagram above but coil around each other into the infamous double helix.
Which Flu? An amazing image from informationisbeautiful.net

I have been neglecting my blog recently for which I apologise…. It is difficult in term time to keep up with putting new material on here with so much else going on. But we have half term starting next Friday so I will be posting iGCSE and pre-U material each day next week.
If anyone has any requests for topics they would like to see included, please contact me via a comment on this site or via Twitter ?
?
